Explanation of Chunk Ensembling
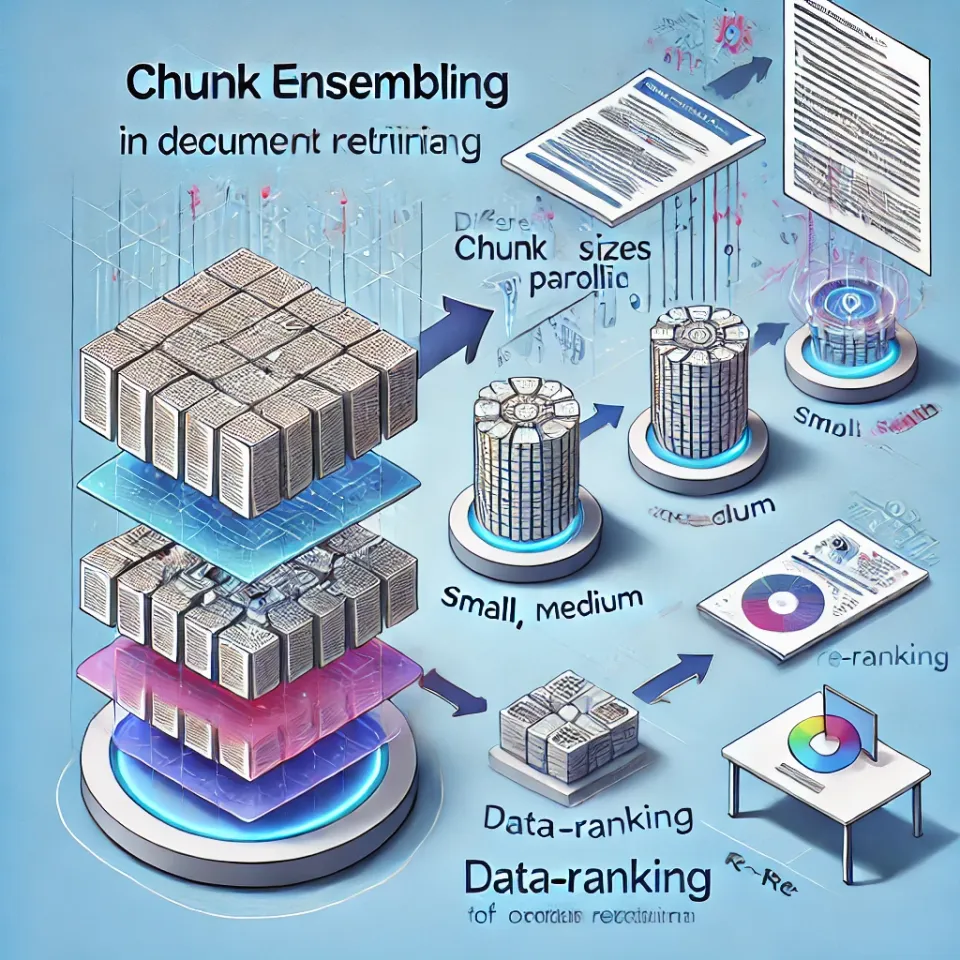
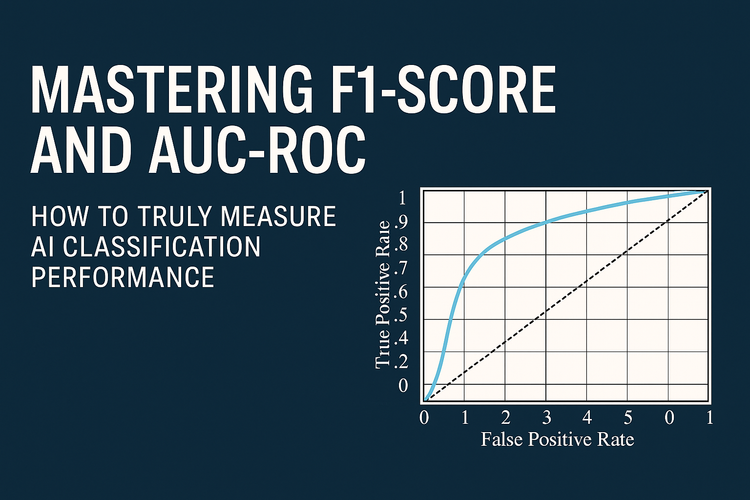
Chunk Ensembling is a retrieval optimization technique that balances precision and context by retrieving multiple chunk sizes simultaneously and re-ranking them for relevance. Instead of relying on only one chunk size, this approach ensures that the system retrieves both small, highly precise chunks and larger, context-rich chunks, providing a more comprehensive retrieval experience.
How Chunk Ensembling Works
- Multi-Scale Chunk Indexing
- The document is indexed in multiple ways:
- Small chunks (128-256 tokens) for precise matching.
- Medium chunks (512-1024 tokens) for sentence and paragraph-level context.
- Large chunks (2000+ tokens) for broader document understanding.
- The document is indexed in multiple ways:
- Parallel Retrieval
- When a query is made, the retrieval system fetches multiple chunk sizes simultaneously from a vector database (e.g., FAISS, Pinecone, Weaviate).
- The system ensures that both detailed fact-level and contextually relevant information is retrieved.
- Re-Ranking the Results
- Once different-sized chunks are retrieved, they are scored based on:
- Semantic similarity to the query.
- Context completeness (whether enough supporting details exist).
- Query intent alignment (whether the chunk directly answers the user’s need).
- The best chunk (or combination of chunks) is selected for final retrieval.
- Once different-sized chunks are retrieved, they are scored based on:
- Dynamic Merging of Chunks (If Needed)
- If small chunks alone lack context, the system dynamically merges them to form a coherent response before passing the final result to the LLM.
Why Use Chunk Ensembling?
- Improves Accuracy – Ensures that retrieval includes both precise answers and full context.
- Reduces Hallucination – By merging chunks dynamically, it prevents the model from making assumptions.
- Optimizes LLM Input – Sends the most relevant data into the LLM, reducing token waste.
- Enhances User Experience – Responses become more informative, improving AI comprehension.
Here's a Python implementation of Chunk Ensembling, demonstrating how to retrieve multiple chunk sizes and re-rank them for the best result. This example assumes the use of FAISS (Facebook AI Similarity Search) for vector storage and BM25 (text-based retrieval) for keyword search.
import faiss
import numpy as np
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer
# Load a sentence embedding model
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
# Example document chunks (simulating multiple chunk sizes)
documents = [
"AI is transforming industries worldwide.", # Small chunk (128 tokens)
"Artificial intelligence is being used in healthcare, finance, and technology sectors to improve efficiency and decision-making.", # Medium chunk (512 tokens)
"Over the past decade, machine learning and deep learning models have been widely adopted in various industries, offering unprecedented levels of automation and insights into data-driven decision-making processes.", # Large chunk (1024 tokens)
]
# Compute embeddings for each chunk
chunk_embeddings = np.array([embedding_model.encode(doc) for doc in documents])
# Create a FAISS index (for vector search)
dimension = chunk_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension) # L2 distance-based search
index.add(chunk_embeddings) # Store vectors
# BM25 keyword search setup
tokenized_docs = [doc.split(" ") for doc in documents]
bm25 = BM25Okapi(tokenized_docs)
def ensemble_retrieval(query, k=2):
"""
Retrieves relevant chunks using both FAISS (vector search) and BM25 (keyword-based search).
Re-ranks them based on combined scores.
"""
# Compute embedding for query
query_embedding = embedding_model.encode(query).reshape(1, -1)
# FAISS Vector Search
_, faiss_results = index.search(query_embedding, k) # Retrieve top-k vector matches
# BM25 Keyword Search
bm25_scores = bm25.get_scores(query.split()) # BM25 relevance scores
# Normalize BM25 scores (0-1 scaling)
bm25_scores = np.array(bm25_scores)
bm25_scores = (bm25_scores - bm25_scores.min()) / (bm25_scores.max() - bm25_scores.min() + 1e-5)
# Aggregate scores (Weighted sum of FAISS & BM25)
combined_scores = []
for i in range(len(documents)):
vector_rank = -np.linalg.norm(chunk_embeddings[i] - query_embedding) # Higher is better
combined_score = 0.5 * vector_rank + 0.5 * bm25_scores[i] # Adjust weighting as needed
combined_scores.append((combined_score, documents[i]))
# Sort results by best combined score
ranked_results = sorted(combined_scores, key=lambda x: x[0], reverse=True)
return [doc for _, doc in ranked_results[:k]]
# Example Query
query_text = "How is AI transforming industries?"
results = ensemble_retrieval(query_text, k=3)
# Display results
print("\n🔹 Top Retrieved Chunks:")
for i, res in enumerate(results):
print(f"{i+1}. {res}")
Explanation of the Code
- Multi-Scale Chunking
- We store small (128 tokens), medium (512 tokens), and large chunks (1024 tokens) in a vector database (FAISS).
- BM25 is used for exact keyword search to complement semantic retrieval.
- Dual Retrieval Mechanism
- FAISS Vector Search: Finds the closest semantic matches to the query.
- BM25 Keyword Search: Identifies exact word matches for relevance.
- Re-Ranking Strategy
- FAISS matches are ranked by vector distance.
- BM25 scores are normalized and combined.
- The final ranking selects the most relevant chunk(s) using a weighted score.
Example Output