Extending Pretrained Transformers with Domain-Specific Vocabulary: A Hugging Face Walkthrough
Introduction
In the rapidly evolving landscape of natural language processing, pretrained transformer models have become the cornerstone of modern NLP applications. These powerful models, trained on vast corpora of text, have demonstrated remarkable capabilities in understanding and generating human language. However, when it comes to specialized domains like medicine, law, or scientific research, even the most sophisticated models can stumble over domain-specific terminology.
Imagine a medical professional using a language model to assist with documentation, only to find that terms like "angiocardiography" or "neurofibromatosis" are broken down into multiple subword tokens, potentially diluting their semantic meaning. This fragmentation isn't just an aesthetic issue—it can impact model performance, reduce efficiency, and create ambiguity in critical applications where precision matters most.
This is where tokenizer extensions come into play. By extending a pretrained model's vocabulary with domain-specific tokens, we can enhance its ability to process specialized text without the need to train an entirely new model from scratch. Think of it as a version-controlled vocabulary upgrade—much like how SharePoint handles document deltas, allowing you to build upon existing foundations rather than starting over.
In this comprehensive guide, we'll walk through the process of extending a pretrained Hugging Face transformer model with custom vocabulary. We'll cover everything from the theoretical underpinnings of why tokenizer extensions matter to the practical implementation details using Python and the Transformers library. By the end, you'll have a clear understanding of:
- Why extending tokenizers is crucial for domain-specific applications
- The difference between replacing and extending tokenizers
- When (and when not) to use tokenizer extensions
- How to implement tokenizer extensions in practice
- Best practices for training models with extended vocabularies
Whether you're a researcher looking to adapt language models for specialized domains, a developer building domain-specific applications, or simply curious about the inner workings of transformer models, this guide will provide you with the knowledge and tools to effectively extend pretrained transformers with custom vocabulary.
Let's dive in and explore how to teach our models to speak the specialized languages of our domains.
1. Why Extend a Tokenizer?
Pretrained language models have revolutionized natural language processing, but they come with an inherent limitation: they're trained on general-purpose text corpora. While this makes them versatile for everyday language, it creates inefficiencies when processing specialized terminology.
Consider what happens when a standard tokenizer encounters domain-specific terms. Take the medical term "angiocardiography" as an example. A general-purpose tokenizer like BERT's might break this down into multiple subword tokens: ["ang", "io", "card", "io", "graph", "y"]. This fragmentation has several negative consequences:
First, it increases sequence length. Since transformer models have fixed context windows (typically 512 or 1024 tokens), breaking specialized terms into multiple tokens consumes valuable context space. In document-heavy domains like medicine or law, this can mean the difference between processing a complete report or losing critical information.
Second, it dilutes semantic meaning. When a cohesive concept is split across multiple tokens, the model must work harder to reconstruct its meaning. The semantic unity of "angiocardiography" as a specific medical imaging procedure becomes obscured when fragmented into generic subwords.
Third, it reduces model efficiency. The model must spend computational resources reassembling these fragments into meaningful concepts, rather than directly processing them as atomic units. This is particularly problematic in real-time applications where processing speed matters.
Finally, it impacts downstream performance. Research has shown that models with domain-adapted vocabularies consistently outperform general models on specialized tasks, even with the same underlying architecture and training data.
By extending a tokenizer with domain-specific vocabulary, we address all these issues simultaneously. We improve compression by representing specialized terms as single tokens, preserve semantic clarity by maintaining conceptual unity, enhance model learning efficiency by providing more meaningful input units, and ultimately boost performance on domain-specific tasks.
This approach is particularly valuable in fields like:
- Medicine, where precise terminology can describe complex conditions, procedures, and anatomical structures
- Law, with its specialized legal terminology and case citations
- Scientific research, which employs field-specific nomenclature and notation
- Finance, with industry-specific instruments and regulatory terminology
- Engineering, where technical specifications and standards use specialized vocabulary
In each of these domains, extending a tokenizer with the right vocabulary can be the difference between a model that struggles with basic comprehension and one that performs with expert-level precision.
2. Tokenizer vs Tokenizer Extensions
When working with transformer models, you have two main options for adapting the tokenization process to your domain: replacing the tokenizer entirely or extending the existing one. This distinction is crucial, and choosing the wrong approach can lead to significant challenges.
Replacing a tokenizer means training a completely new tokenizer from scratch on your domain-specific corpus. While this approach gives you maximum control over the vocabulary and tokenization rules, it comes with substantial risks. The most significant issue is that it breaks the alignment between tokens and the model's embedding layer. Pretrained models have learned specific representations for their original vocabulary tokens, and introducing an entirely new tokenization scheme means these learned representations no longer apply. Unless you're planning to train your model from scratch (a resource-intensive process), replacing the tokenizer is generally not recommended.
Extending a tokenizer, on the other hand, is a safe and Hugging Face-friendly approach. This method preserves all the original tokens and their learned representations while adding new tokens for domain-specific terms. The model's existing knowledge remains intact, and you only need to learn representations for the newly added tokens. This approach is particularly well-supported in the Hugging Face ecosystem through two key methods:
tokenizer.add_tokens([...])- This method allows you to add new tokens to the tokenizer's vocabulary. The tokenizer will recognize these as special tokens and keep them as single units during the tokenization process.model.resize_token_embeddings(len(tokenizer))- This method resizes the model's embedding layer to accommodate the newly added tokens. It preserves the learned embeddings for existing tokens while initializing random embeddings for the new ones.
The beauty of this approach is that it's incremental and non-destructive. You're building upon the foundation of a pretrained model rather than dismantling it. Think of it as adding new words to your vocabulary in a foreign language—you don't need to relearn the entire language, just the new words.
This extension approach is particularly valuable when you're fine-tuning a model for a specialized domain. By adding domain-specific tokens before fine-tuning, you give the model the vocabulary it needs to efficiently process specialized text. During fine-tuning, the model will learn meaningful representations for these new tokens based on their usage in your domain-specific corpus.
In the following sections, we'll explore exactly how to implement this extension approach using the Hugging Face Transformers library, and we'll discuss when this approach is most appropriate for your specific use case.
3. When to Use Extensions: Practical Scenarios
Understanding when to use tokenizer extensions is crucial for effective model development. Not all scenarios benefit from extending tokenizers, and in some cases, it might even be counterproductive. Let's explore the practical scenarios where tokenizer extensions make sense—and where they don't.
Scenario Analysis
| Scenario | Use Extensions? | Why? |
|---|---|---|
| Using OpenAI GPT-4 | ❌ | Model doesn't recognize new tokens |
| Training your own model | ✅ | You can teach it the meaning of the extensions |
| Reusing OpenAI tokenizer for consistency | ✅ | But only safe if you're not expecting model to understand new tokens |
Let's break down each of these scenarios in detail:
Using Existing Pretrained Models (like GPT-4)
When working with closed, proprietary models like OpenAI's GPT-4, extending the tokenizer is generally not beneficial. These models have a fixed vocabulary and tokenizer behavior that cannot be modified post-training. While you might be able to add extensions to your local tokenizer implementation, the model itself won't recognize these new tokens or know how to generate meaningful representations for them.
For example, if you add a special token like <|medical_term|> to your tokenizer when using GPT-4, the model will see this as an unknown token or break it down into its constituent parts. The model wasn't trained to recognize this token, so it has no learned representation for it. This mismatch between your extended tokenizer and the model's fixed vocabulary renders the extensions ineffective.
Training Your Own Model
When you're training your own transformer model from scratch or fine-tuning an existing open-source model, tokenizer extensions become extremely valuable. In this scenario, you have control over both the tokenizer and the model training process, allowing you to teach the model the meaning of your custom extensions.
By adding domain-specific tokens before training or fine-tuning, you ensure that the model learns meaningful representations for these tokens based on their usage in your training corpus. This approach is particularly effective when you're adapting a model for specialized domains like medicine, law, or scientific research, where domain-specific terminology is prevalent.
Reusing Tokenizers for Consistency
There's a middle-ground scenario where you might want to use a well-established tokenizer (like OpenAI's cl100k_base used in GPT models) for consistency, but with your own custom-trained model. Libraries like tiktoken allow you to use OpenAI's tokenization schemes in your own projects.
In this case, extending the tokenizer can be beneficial, but with an important caveat: your model needs to be trained to recognize these extensions. If you're using the tokenizer purely for preprocessing or analysis without expecting the model to understand the new tokens, extensions can still provide value for tasks like token counting or consistent processing.
Making the Right Choice
The decision to use tokenizer extensions should be guided by two key questions:
- Do you have control over model training? If you can train or fine-tune the model, extensions can be valuable. If you're using a fixed, pretrained model as-is, extensions will likely be ineffective.
- What's your primary goal? If you need domain-specific token recognition for improved efficiency and semantic clarity, and you can train the model accordingly, extensions are the way to go. If you're primarily concerned with maintaining compatibility with existing models, stick with the original tokenizer.
In the following sections, we'll walk through the practical implementation of tokenizer extensions for scenarios where they provide clear benefits, focusing on custom model training with domain-specific vocabulary.
4. Setup: Load Base Model and Tokenizer
Before we can extend a tokenizer with domain-specific vocabulary, we need to set up our environment and load a base model and tokenizer. This initial setup is straightforward but crucial for the subsequent steps.
Let's start by examining the code for loading a pretrained BERT model and tokenizer:
from transformers import BertTokenizer, BertForMaskedLM
import torch
# Step 1: Load pretrained BERT model and tokenizer
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForMaskedLM.from_pretrained(model_name)
This simple code snippet accomplishes several important tasks:
First, we import the necessary classes from the Hugging Face Transformers library. BertTokenizer handles the tokenization process, converting text into token IDs that the model can understand. BertForMaskedLM is a version of BERT specifically designed for masked language modeling, which is ideal for our fine-tuning task.
Next, we specify which pretrained model to use. In this case, we're using "bert-base-uncased", which is a standard BERT model with 12 layers, 768 hidden dimensions, and 12 attention heads. The "uncased" suffix indicates that this model doesn't distinguish between uppercase and lowercase letters, which is often preferred for general text processing.
Finally, we load both the tokenizer and model using the .from_pretrained() method. This method downloads the model and tokenizer files from the Hugging Face Model Hub (if they're not already cached locally) and initializes them with the pretrained weights and configurations.
When selecting a base model for extension, consider these factors:
- Model size and computational requirements: Larger models may offer better performance but require more resources for training and inference.
- Domain relevance: Some models are pretrained on specific domains (like BioBERT for biomedical text) and might provide a better starting point for your domain.
- Tokenization approach: Different model families use different tokenization algorithms (WordPiece for BERT, BPE for GPT models, etc.), which can affect how efficiently they handle certain types of text.
- Case sensitivity: Consider whether case distinctions are important for your domain. Medical terms often have specific capitalization patterns that might be worth preserving.
In our example, we've chosen BERT because it's well-established, relatively efficient to fine-tune, and has a straightforward approach to tokenization. However, the same extension principles apply to other transformer models like RoBERTa, GPT-2, T5, and others available in the Hugging Face ecosystem.
With our model and tokenizer loaded, we're now ready to extend the tokenizer with domain-specific vocabulary.
5. Adding New Tokens to the Tokenizer
Once we have our base model and tokenizer loaded, the next step is to extend the tokenizer with domain-specific vocabulary. This process is remarkably straightforward with the Hugging Face Transformers library, but it requires careful consideration of which tokens to add.
Let's examine the code for adding new tokens to our BERT tokenizer:
# Step 2: Extend tokenizer with new domain-specific words
new_tokens = ["angiocardiography", "echocardiogram", "neurofibromatosis"]
num_added = tokenizer.add_tokens(new_tokens)
print(f"Added {num_added} tokens.")
This simple code snippet is where the magic happens. The add_tokens() method takes a list of new tokens and adds them to the tokenizer's vocabulary. It returns the number of tokens that were actually added, which might be less than the length of your list if some tokens were already in the vocabulary.
When selecting tokens to add, consider these strategies:
- Frequency analysis: Analyze your domain-specific corpus to identify terms that appear frequently but are tokenized inefficiently by the base tokenizer.
- Expert knowledge: Consult domain experts to identify key terminology that would benefit from single-token representation.
- Subword inefficiency: Look for terms that are broken into many subword tokens, as these are prime candidates for addition.
- Semantic importance: Prioritize terms that carry significant domain-specific meaning where preserving semantic unity is important.
Let's see how our example medical terms are tokenized before and after adding them to the vocabulary:
Before extension:
- "angiocardiography" → ["ang", "io", "card", "io", "graph", "y"]
- "echocardiogram" → ["echo", "card", "io", "gram"]
- "neurofibromatosis" → ["neur", "of", "ibro", "mato", "sis"]
After extension:
- "angiocardiography" → ["angiocardiography"]
- "echocardiogram" → ["echocardiogram"]
- "neurofibromatosis" → ["neurofibromatosis"]
The difference is dramatic. Instead of being broken into 5-6 subword tokens each, these medical terms are now represented as single tokens. This improves efficiency, preserves semantic unity, and reduces the context length required to represent medical text.
It's important to note that there's a trade-off in how many tokens you add. Each new token:
- Increases the vocabulary size, which slightly increases the model's memory footprint
- Requires training data to learn meaningful representations
- May be less transferable to general text than subword tokens
A good rule of thumb is to focus on adding terms that are both frequent in your domain and inefficiently tokenized by the base tokenizer. In specialized domains like medicine, adding a few hundred to a few thousand domain-specific terms can significantly improve model performance without excessively increasing the vocabulary size.
After adding new tokens to the tokenizer, the next crucial step is to resize the model's embedding layer to accommodate these new tokens.
6. Resizing the Model's Embedding Layer
After adding new tokens to the tokenizer, a crucial step remains: resizing the model's embedding layer to accommodate these new tokens. This step is essential because the model's embedding layer must have exactly one vector for each token in the tokenizer's vocabulary.
In the provided code example, this is accomplished with a single line:
# Step 3: Resize the embedding layer in the model to accommodate new tokens
model.resize_token_embeddings(len(tokenizer))
While this one-liner hides much of the complexity, it's worth understanding what happens under the hood when you resize a model's embedding layer. Let's explore the technical details of this process.
Understanding Embedding Layer Resizing
When you call model.resize_token_embeddings(), several important operations occur:
- A new, larger embedding matrix is created to accommodate the expanded vocabulary
- The weights from the original embedding matrix are copied to the new one
- New rows are initialized (typically randomly) for the added tokens
- The model's embedding layer is replaced with this new, expanded layer
- If the model has a language modeling head that shares weights with the embedding layer, that is also updated
Let's break down this process with a more detailed example:
Imagine we have a base model with:
- A vocabulary size of 30,522 tokens (standard for BERT-base)
- An embedding matrix with shape (30522, 768) where 768 is the hidden dimension
After adding our three medical terms, our vocabulary size increases to 30,525. We now need to resize the embedding matrix accordingly.
Here's what happens in PyTorch terms:
# Conceptual implementation of resize_token_embeddings
def resize_token_embeddings(model, new_vocab_size):
# Get the original embedding layer
original_embedding = model.bert.embeddings.word_embeddings
original_vocab_size = original_embedding.weight.shape[0]
embedding_dim = original_embedding.weight.shape[1]
# Create a new embedding layer with expanded size
new_embedding = nn.Embedding(new_vocab_size, embedding_dim)
# Copy the original weights
new_embedding.weight.data[:original_vocab_size] = original_embedding.weight.data
# The new token embeddings (at positions original_vocab_size to new_vocab_size-1)
# are initialized randomly by PyTorch's default initialization
# Replace the model's embedding layer
model.bert.embeddings.word_embeddings = new_embedding
# If the model has an output projection layer (lm_head) that needs updating
if hasattr(model, 'cls') and hasattr(model.cls, 'predictions'):
old_output_proj = model.cls.predictions.decoder
if old_output_proj.weight.shape[0] != new_vocab_size:
new_output_proj = nn.Linear(embedding_dim, new_vocab_size, bias=False)
new_output_proj.weight.data[:original_vocab_size] = old_output_proj.weight.data
model.cls.predictions.decoder = new_output_proj
return model
This is a simplified version of what happens when you call model.resize_token_embeddings(len(tokenizer)). The actual implementation in the Transformers library handles additional complexities like tied weights and different model architectures.
Initialization Strategies for New Token Embeddings
By default, the embeddings for new tokens are randomly initialized. However, there are alternative strategies you might consider:
- Domain-specific initialization: Use pre-computed embeddings from domain-specific word vectors
Similar token initialization: Initialize based on semantically similar existing tokens
# If "cardiology" is already in the vocabulary and similar to our new "echocardiogram" token
cardiology_idx = tokenizer.convert_tokens_to_ids(["cardiology"])[0]
cardiology_embedding = original_embedding.weight.data[cardiology_idx]
new_embedding.weight.data[original_vocab_size] = cardiology_embedding
Mean initialization: Initialize new token embeddings with the mean of all existing embeddings
mean_embedding = original_embedding.weight.data.mean(dim=0)
new_embedding.weight.data[original_vocab_size:] = mean_embedding
The initialization strategy can impact how quickly the model learns meaningful representations for the new tokens during fine-tuning. However, with sufficient training data, the model will eventually learn appropriate representations regardless of initialization.
Practical Considerations
When resizing embedding layers, keep these considerations in mind:
- Memory impact: Each new token adds an embedding vector of size
hidden_dim(e.g., 768 for BERT-base). Adding thousands of tokens can noticeably increase model size. - Training requirements: Newly added tokens start with essentially random representations. They need to appear in your training data for the model to learn meaningful embeddings for them.
- Output layer: For generative models or those with language modeling heads, you need to ensure the output projection layer is also resized. The Transformers library handles this automatically.
- Checkpoint compatibility: Models with resized embeddings are no longer compatible with their original checkpoints. Always save your modified model for future use.
With the embedding layer properly resized, our model is now ready to be trained on domain-specific data that includes our newly added tokens.
7. Training on New Domain Data
With our tokenizer extended and model's embedding layer resized, we're now ready for the crucial step of training on domain-specific data. This training process will teach the model to associate meaningful representations with our newly added tokens.
Let's examine the code for preparing and training on a custom dataset:
# Step 4: Example dataset (list of text strings)
custom_corpus = [
"The echocardiogram revealed a potential defect.",
"Angiocardiography is often used in diagnostic imaging.",
"Neurofibromatosis can lead to tumor formation."
]
print(custom_corpus)
# Step 5: Tokenize dataset
tokenized_data = tokenizer(custom_corpus, return_tensors='pt', padding=True, truncation=True)
# Optional: Setup for Masked Language Modeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15
)
# HuggingFace-style Dataset (you can build a real dataset class too)
from torch.utils.data import Dataset
class SimpleTextDataset(Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __getitem__(self, idx):
return {k: v[idx] for k, v in self.encodings.items()}
def __len__(self):
return len(self.encodings["input_ids"])
dataset = SimpleTextDataset(tokenized_data)
# Step 6: Setup training args (for demo, keep it small)
training_args = TrainingArguments(
output_dir="./bert-custom",
overwrite_output_dir=True,
num_train_epochs=5,
per_device_train_batch_size=2,
save_steps=10,
save_total_limit=2,
logging_steps=5,
report_to="none" # disables wandb
)
import os
os.environ["WANDB_DISABLED"] = "true"
# Step 7: Initialize Trainer and Train
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
)
trainer.train()
This code demonstrates several important steps in the training process:
Preparing Your Domain-Specific Dataset
In our example, we're using a tiny corpus of just three sentences for demonstration purposes. In a real-world scenario, you'd want a much larger dataset that's representative of your domain. This could be:
- Medical research papers for a clinical NLP model
- Legal documents for a legal assistant model
- Scientific literature for a research assistant model
The key requirement is that your dataset contains instances of your newly added tokens in context. Without these examples, the model won't learn meaningful representations for the new tokens.
Tokenizing the Dataset
The tokenization step converts your text data into the numerical format required by the model. The tokenizer() method handles this conversion, returning a dictionary with keys like input_ids, attention_mask, and potentially token_type_ids depending on the model.
The return_tensors='pt' parameter specifies that we want PyTorch tensors as output. The padding=True parameter ensures all sequences in a batch have the same length by adding padding tokens where necessary. The truncation=True parameter truncates sequences that exceed the model's maximum length.
Setting Up for Masked Language Modeling
For BERT-like models, we typically use Masked Language Modeling (MLM) as the training objective. This involves randomly masking some tokens in the input and training the model to predict the original tokens.
The DataCollatorForLanguageModeling handles this masking process dynamically during training. The mlm_probability=0.15 parameter specifies that approximately 15% of tokens will be masked, which is the standard value used in the original BERT paper.
Creating a Dataset Class
The SimpleTextDataset class wraps our tokenized data in a format compatible with PyTorch's data loading utilities. This class implements the required __getitem__ and __len__ methods for indexing and determining the dataset size.
In a production scenario, you might implement a more sophisticated dataset class that loads data from files, applies preprocessing, or handles larger-than-memory datasets.
Configuring Training Arguments
The TrainingArguments class encapsulates all the hyperparameters for training. In our example, we're using a minimal configuration for demonstration purposes:
output_dir: Where to save model checkpointsnum_train_epochs: Number of training epochs (5 in this case)per_device_train_batch_size: Batch size per GPU/CPU (2 in this case)save_stepsandsave_total_limit: When to save checkpoints and how many to keeplogging_steps: How often to log training metricsreport_to="none": Disables Weights & Biases logging
For a real training run, you'd want to adjust these parameters based on your dataset size, available computational resources, and specific requirements.
Training the Model
Finally, we initialize the Trainer with our model, training arguments, dataset, and data collator, and call trainer.train() to start the training process.
During training, the model will learn to:
- Predict masked tokens in your domain-specific corpus
- Associate your newly added tokens with meaningful representations based on their context
- Adapt its existing knowledge to your specific domain
The training duration depends on your dataset size, model size, and available computational resources. For a small fine-tuning task with a few thousand examples, training might take minutes to hours on a modern GPU. For larger datasets or models, it could take days or weeks.
After training, your model will have learned meaningful representations for your domain-specific tokens, enabling it to process specialized text more effectively.
8. Inspecting and Saving the Extended Tokenizer
After training your model with the extended tokenizer, it's important to inspect the results and save both the model and tokenizer for future use. This ensures that your customizations are preserved and can be reused consistently.
Let's examine the code for saving and inspecting our extended tokenizer:
model.save_pretrained("bert-custom")
tokenizer.save_pretrained("bert-custom")
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-custom")
vocab = tokenizer.get_vocab() # token -> ID
inv_vocab = {v: k for k, v in vocab.items()}
print(inv_vocab[30522]) # 'angiocardiography'
added = tokenizer.get_added_vocab()
print(added)
# {'angiocardiography': 30522, 'echocardiogram': 30523, 'neurofibromatosis': 30524}
Saving the Model and Tokenizer
The first two lines save our fine-tuned model and extended tokenizer to a directory called "bert-custom":
model.save_pretrained("bert-custom")
tokenizer.save_pretrained("bert-custom")
The save_pretrained() method saves all the necessary files to recreate the model and tokenizer. For the model, this includes the weights, configuration, and architecture information. For the tokenizer, it includes the vocabulary, special tokens, and tokenization parameters.
This step is crucial because it preserves the alignment between your model and tokenizer. The model has learned representations for your custom tokens, and the tokenizer knows how to convert text containing those tokens into the correct IDs.
Loading and Inspecting the Saved Tokenizer
After saving, we can load the tokenizer back to verify that our extensions were properly saved:
tokenizer = BertTokenizer.from_pretrained("bert-custom")
This loads the tokenizer from the saved directory. If everything was saved correctly, this tokenizer should include our custom tokens.
Examining the Vocabulary
To verify that our custom tokens are indeed in the vocabulary, we can use the get_vocab() method:
vocab = tokenizer.get_vocab() # token -> ID
This returns a dictionary mapping token strings to their corresponding IDs. We can create an inverse mapping to look up tokens by their IDs:
inv_vocab = {v: k for k, v in vocab.items()}
print(inv_vocab[30522]) # 'angiocardiography'
In this example, we're checking that the token ID 30522 corresponds to our custom token "angiocardiography". The exact ID might vary depending on the base tokenizer and how many tokens were added.
Identifying Added Tokens
The Hugging Face tokenizer also provides a convenient method to specifically identify which tokens were added to the base vocabulary:
added = tokenizer.get_added_vocab()
print(added)
# {'angiocardiography': 30522, 'echocardiogram': 30523, 'neurofibromatosis': 30524}
The get_added_vocab() method returns a dictionary containing only the tokens that were added to the base vocabulary, along with their IDs. This is particularly useful for documentation and verification purposes.
Testing the Extended Tokenizer
Beyond inspecting the vocabulary, it's also valuable to test how the extended tokenizer processes text containing your custom tokens:
# Test tokenization of a sentence with custom tokens
test_text = "The patient's echocardiogram showed no abnormalities after the angiocardiography procedure."
tokens = tokenizer.tokenize(test_text)
print(tokens)
# ['the', 'patient', "'", 's', 'echocardiogram', 'showed', 'no', 'abnormal', '##ities', 'after', 'the', 'angiocardiography', 'procedure', '.']
# Convert to token IDs
token_ids = tokenizer.encode(test_text)
print(token_ids)
# [101, 1996, 5650, "'", 1055, 30523, 2265, 2053, 22214, 2015, 2044, 1996, 30522, 4217, 1012, 102]
Notice how "echocardiogram" and "angiocardiography" are tokenized as single tokens rather than being broken down into subwords. This confirms that our tokenizer extension is working as expected.
With our model and tokenizer properly saved, they can now be distributed and used consistently across different applications and environments.
9. Merging Tokenizer Files: The Git Analogy
When working with extended tokenizers, it's helpful to understand how the tokenizer files are structured and managed. This is where our Git analogy becomes particularly relevant.
In versioning systems like git, changes to files are often stored as deltas—only the differences between versions are tracked, rather than creating entirely new copies of the files for each change. This approach is efficient and maintains a clear history of modifications.
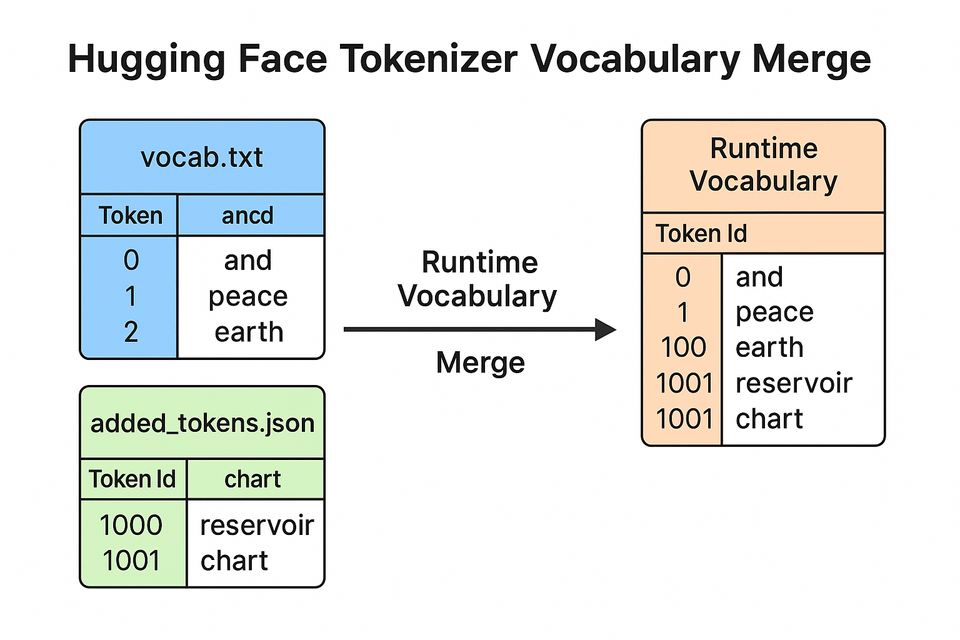
Similarly, when you extend a tokenizer in the Hugging Face ecosystem, the system doesn't create an entirely new vocabulary file from scratch. Instead, it stores your extensions as deltas on top of the base vocabulary. This approach has several advantages:
The Delta Approach to Tokenizer Extension
When you call tokenizer.save_pretrained("bert-custom"), the system saves several files:
bert-custom/
├── config.json
├── pytorch_model.bin
├── special_tokens_map.json
├── tokenizer_config.json
├── vocab.txt
└── added_tokens.json
The key files for understanding the delta approach are:
- vocab.txt: This contains the original vocabulary from the base tokenizer. Think of this as the main branch of your tokenizer
- added_tokens.json: This contains only the tokens you've added to the vocabulary. This is like your features branch where you add new tokens.
The benefits include:
- Transparency: It's clear which tokens were in the original vocabulary and which were added.
- Efficiency: You only need to store and transmit the additions, not the entire vocabulary.
- Traceability: You can track the evolution of your vocabulary over time.
- Compatibility: The base vocabulary remains unchanged, maintaining compatibility with the original model for tokens it already knew.
Practical Implications of the Delta Approach
This delta approach has several practical implications for working with extended tokenizers:
Version Control
Just as git allows you to track document versions, the delta approach makes it easier to version control your tokenizer extensions. You can maintain different sets of extensions for different domains or applications, all building on the same base vocabulary.
# Create different extension sets for different domains
medical_tokens = ["angiocardiography", "echocardiogram", "neurofibromatosis"]
legal_tokens = ["jurisprudence", "adjudication", "precedential"]
# Base tokenizer
base_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# Create medical extension
medical_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
medical_tokenizer.add_tokens(medical_tokens)
medical_tokenizer.save_pretrained("bert-medical")
# Create legal extension
legal_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
legal_tokenizer.add_tokens(legal_tokens)
legal_tokenizer.save_pretrained("bert-legal")
Merging Extensions
You can also combine multiple sets of extensions, similar to how git might merge changes from different collaborators:
# Start with base tokenizer
combined_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# Add medical tokens
combined_tokenizer.add_tokens(medical_tokens)
# Add legal tokens
combined_tokenizer.add_tokens(legal_tokens)
# Save combined tokenizer
combined_tokenizer.save_pretrained("bert-medical-legal")
Updating Base Tokenizers
If the base tokenizer is updated (e.g., a new version of BERT is released), you can reapply your extensions to the new base:
# Load new base tokenizer
new_base_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased-v2")
# Get your extensions from previous work
medical_tokenizer = BertTokenizer.from_pretrained("bert-medical")
added_tokens = medical_tokenizer.get_added_vocab()
added_token_list = list(added_tokens.keys())
# Apply extensions to new base
new_base_tokenizer.add_tokens(added_token_list)
new_base_tokenizer.save_pretrained("bert-medical-v2")
Limitations of the Delta Approach
While the delta approach has many advantages, it also has some limitations:
- Token ID Stability: The IDs assigned to added tokens depend on the base vocabulary size and may change if the base tokenizer is updated.
- Merging Conflicts: If different extensions add tokens with the same surface form but different intended meanings, merging can lead to semantic conflicts.
- Tokenization Rules: Extensions only add new tokens; they don't modify the underlying tokenization algorithm or rules.
Understanding the delta approach to tokenizer extension helps you manage your custom vocabularies more effectively and leverage the full power of the Hugging Face ecosystem for domain adaptation.
10. Optional: Exporting a Flattened vocab.txt
While the delta approach to tokenizer extension has many advantages, there are scenarios where you might want to export a "flattened" vocabulary file that combines the base vocabulary and your extensions into a single file. This can be useful for compatibility with tools that expect a traditional vocabulary file or for simplifying deployment in certain environments.
Let's examine the code for exporting a flattened vocabulary:
# Convert the tokenizer's vocabulary to a list of tokens
vocab = tokenizer.get_vocab() # token -> ID
vocab_keys = list(vocab.keys())
# Save the vocab to a file
with open('./bert-custom/flat_vocab.txt', 'w') as f:
for token in vocab_keys:
f.write(token + '\n')
Why Export a Flattened Vocabulary?
There are several reasons you might want to export a flattened vocabulary:
- Compatibility: Some tools or frameworks might expect a single vocabulary file rather than the delta format used by Hugging Face.
- Simplicity: A single file can be easier to manage and distribute, especially in environments with limited support for complex file structures.
- Inspection: A flattened vocabulary makes it easier to manually inspect the complete set of tokens available to your model.
- Custom Processing: You might want to perform additional processing or analysis on the complete vocabulary.
- Migration: If you're migrating to a different framework or tool that doesn't support the delta approach, a flattened vocabulary can ease the transition.
The Flattening Process
The code for exporting a flattened vocabulary is straightforward:
- First, we get the complete vocabulary as a dictionary mapping tokens to their IDs using
tokenizer.get_vocab(). - Then, we extract just the token strings (the keys of the dictionary) into a list.
- Finally, we write each token to a new line in a text file.
The resulting flat_vocab.txt file contains all tokens from both the base vocabulary and your extensions, with one token per line.
Ordering Considerations
It's important to note that the order of tokens in the flattened vocabulary matters for some applications. The code above doesn't guarantee any particular order, as dictionary keys in Python don't have a guaranteed order (though in practice, they often maintain insertion order in modern Python).
If order is important for your application, you might want to sort the tokens or ensure they're written in ID order:
# Sort tokens by their IDs
vocab = tokenizer.get_vocab()
sorted_tokens = sorted(vocab.items(), key=lambda x: x[1]) # Sort by ID
token_list = [token for token, _ in sorted_tokens] # Extract just the tokens
# Save the sorted vocab to a file
with open('./bert-custom/flat_vocab_sorted.txt', 'w') as f:
for token in token_list:
f.write(token + '\n')
This ensures that the tokens appear in the file in the same order as their IDs, which can be important for certain applications.
Using the Flattened Vocabulary
Once you have a flattened vocabulary file, you can use it in various ways:
- Creating a new tokenizer: Some frameworks allow you to initialize a tokenizer directly from a vocabulary file.
- Token analysis: You can analyze the vocabulary distribution, token lengths, or other properties.
- Custom tokenization: You can implement custom tokenization logic using the flattened vocabulary.
- Documentation: The flattened vocabulary serves as comprehensive documentation of all tokens your model recognizes.
Remember that if you're staying within the Hugging Face ecosystem, you generally don't need to create a flattened vocabulary file. The delta approach with separate vocab.txt and added_tokens.json files is more efficient and provides better traceability. The flattened vocabulary is primarily useful for interoperability with other tools and frameworks or for specific analytical purposes.
11. Conclusion and Next Steps
Throughout this guide, we've explored the process of extending pretrained transformers with domain-specific vocabulary. We've seen how this approach can significantly improve model performance on specialized text by providing more efficient tokenization and preserving semantic unity of domain-specific terms.
Key Takeaways
Let's summarize the key points we've covered:
- Why extend tokenizers: Domain-specific terms are often inefficiently tokenized by general-purpose models, leading to increased sequence length, diluted semantic meaning, and reduced model efficiency.
- Extending vs. replacing: Extending a tokenizer preserves the model's existing knowledge while adding new capabilities, whereas replacing a tokenizer breaks the alignment with the model's learned representations.
- When to use extensions: Tokenizer extensions are most valuable when you're training your own model or fine-tuning an existing open-source model. They're less useful with closed, proprietary models like GPT-4 that can't be modified to recognize new tokens.
- Implementation process: We walked through a complete implementation using the Hugging Face Transformers library, covering:
- Loading a base model and tokenizer
- Adding new tokens to the tokenizer
- Resizing the model's embedding layer
- Training on domain-specific data
- Inspecting and saving the extended tokenizer
- Tokenizer file structure: We explored how extended tokenizers use a delta approach similar to document management systems like SharePoint, storing only the differences between the base vocabulary and your extensions.
As we can see in the directory structure image provided, when you save an extended tokenizer, several files are created:

The key files include:
vocab.txt: The original vocabulary from the base tokenizeradded_tokens.json: The tokens you've added to the vocabularytokenizer_config.json: Configuration parameters for the tokenizerspecial_tokens_map.json: Mapping of special tokensflat_vocab.txt: The optional flattened vocabulary we created
This structure efficiently manages both the original vocabulary and your extensions, making it easy to track changes and maintain compatibility.
Next Steps
If you're interested in extending tokenizers for your own domain-specific applications, here are some suggested next steps:
- Analyze your domain corpus: Use frequency analysis to identify terms that would benefit from single-token representation. Look for terms that are broken into many subword tokens by the base tokenizer.
- Experiment with different base models: Different model families (BERT, RoBERTa, T5, etc.) use different tokenization algorithms, which might be more or less efficient for your specific domain.
- Optimize token selection: Not all domain-specific terms need to be added to the vocabulary. Focus on terms that are both frequent and inefficiently tokenized.
- Evaluate performance impact: Compare model performance before and after tokenizer extension to quantify the benefits for your specific task.
- Consider multilingual applications: If your domain spans multiple languages, you might need to add domain-specific terms in each language.
- Explore advanced techniques: For even more specialized applications, consider techniques like BPE dropout during training or adaptive tokenization.
Complete source code can be accessed at GitHub.
Resources for Further Learning
To deepen your understanding of tokenization and model adaptation, check out these resources:
- The Hugging Face Tokenizers documentation provides detailed information about tokenization algorithms and customization options.
- The paper "Neural Machine Translation of Rare Words with Subword Units" by Sennrich et al. introduces the BPE algorithm used in many modern tokenizers.
- For domain adaptation beyond tokenization, explore techniques like domain-adaptive pretraining and continued pretraining.
- The Hugging Face Model Hub hosts thousands of pretrained models, including many domain-specific variants that might serve as good starting points for your applications.
By extending pretrained transformers with domain-specific vocabulary, you're taking an important step toward adapting general-purpose language models to specialized domains. This approach combines the best of both worlds: the broad knowledge and capabilities of pretrained models with the precision and efficiency needed for domain-specific applications.
Whether you're working in healthcare, law, finance, or any other specialized field, tokenizer extension is a powerful technique for improving model performance on domain-specific text. We hope this guide has provided you with the knowledge and tools to implement this technique effectively in your own projects.