Hallucinations in LLMs: Why Agentic Applications Are the Solution

Table of Contents
- Introduction
- Understanding Hallucinations
- The Limitations of Scaling
- The Agentic Architecture Solution
- Layer-Specific Hallucination Management
- Industry Trends
- Conclusion
Introduction
Large Language Models (LLMs) have made remarkable progress in recent years, with advances in parameter size, context windows, and inference speed. However, a persistent challenge remains: hallucinations. Even the most advanced models like GPT-4, Claude 3, and Gemini 1.5 continue to generate plausible-sounding but factually incorrect information. This comprehensive analysis explores why the solution to hallucinations may not lie in simply making models bigger or feeding them more tokens, but rather in developing smarter agentic applications with robust verification mechanisms.
Understanding Hallucinations
Definition and Types
Hallucinations in LLMs refer to outputs that are grammatically coherent but factually incorrect or unsupported by any source. These can manifest in various forms:
- Factual Hallucinations: Generating incorrect factual information (e.g., "The Eiffel Tower is in Berlin")
- Numerical Hallucinations: Miscalculating numbers or misrepresenting data (e.g., "GDP of India in 2023 was $12T")
- Source Attribution Hallucinations: Inventing citations, links, or footnotes that don't exist
- Omission Hallucinations: Leaving out necessary context or key steps in processes
- Contradiction Hallucinations: Contradicting earlier outputs within the same session
- Context Drift: Losing track of query scope or goal during generation
- Format Hallucinations: Generating invalid JSON/XML/Function schemas
- Speculative Hallucinations: Making up non-existing features or behaviors
- Tool Hallucinations: Suggesting non-existent tools or functions
- Self-confidence Hallucinations: Expressing high confidence about incorrect information
Why Hallucinations Persist
Hallucinations are not "bugs" in the traditional sense but rather a fundamental side effect of how language models operate. LLMs function as statistical next-token prediction engines, not truth engines. They predict the most probable next token based on patterns in their training data, not necessarily the most factual one.
Several factors contribute to the persistence of hallucinations:
- Prediction vs. Truth: LLMs predict probable text continuations rather than verifying factual accuracy
- Static Knowledge: Once trained, models cannot verify new information without external tools
- Bounded Context: Even with large context windows (up to 1 million tokens), models can still forget, misrepresent, or fabricate details
- Training Limitations: RLHF and alignment fine-tuning reduce but don't eliminate hallucinations
- No Self-Awareness: Models don't inherently know when they're hallucinating
Understanding RLHF and Alignment Fine-tuning
RLHF (Reinforcement Learning from Human Feedback) is a training technique where human evaluators rate model outputs, and these ratings are used to train a reward model. This reward model then guides the fine-tuning of the language model through reinforcement learning, helping it generate more helpful, harmless, and honest responses.
Alignment fine-tuning refers to the process of adjusting a pre-trained language model to better align with human values, preferences, and intentions. This typically involves supervised fine-tuning (SFT) on carefully curated datasets that demonstrate desired behaviors, followed by RLHF to further refine the model's outputs.
While these techniques significantly improve model behavior and reduce certain types of hallucinations (particularly making models less confidently wrong), they don't completely solve the fundamental issue that LLMs are still making statistical predictions rather than reasoning with a grounding in truth. This is why the agentic approach that incorporates external verification and grounding is so important.
The Limitations of Scaling
Why Bigger Models Don't Solve the Problem
The industry initially focused on scaling models to address various limitations, including hallucinations. However, evidence suggests that simply making models larger doesn't solve the hallucination problem:
- Hallucination is Not a Capacity Issue: Even models with hundreds of billions of parameters still hallucinate, sometimes more confidently
- More Context ≠ More Accuracy: Larger context windows allow for more information but don't guarantee it will be used effectively or truthfully
- Training is Bounded by Static Data: Once trained, models cannot verify new information unless retrieval or tools are integrated
- Confidence Without Correctness: Larger models may express higher confidence in incorrect outputs, making hallucinations harder to detect
The Shift to Smaller, Efficient Models
Interestingly, research focus has shifted from building ever-larger models to developing smaller, more efficient ones like BitNet b1.58, Phi-2, TinyLlama, and Mistral 7B. These models are optimized for low-bit inference on CPUs, can run locally with low latency and cost, and perform well enough for many production tasks. While they can't match the depth of large LLMs, they can form effective layers in agentic architectures to help reduce hallucination risk.
How Smaller Models Reduce Hallucinations in Agentic Systems
Smaller models like BitNet b1.58, Phi-2, TinyLlama, and Mistral 7B can help reduce hallucinations in agentic systems in several specific ways:
- Specialized Verification Roles: Smaller models can serve as dedicated critics or verifiers that check the outputs of larger models. They can be fine-tuned specifically for fact-checking and contradiction detection, making them more efficient at catching hallucinations than using another large model.
- Planning and Decomposition: Smaller models excel at structured tasks like breaking down complex queries into simpler steps. They can handle the planning layer of the agentic architecture, ensuring logical consistency and preventing omission hallucinations without needing the full capabilities of larger models.
- Classification and Routing: They can efficiently classify inputs and outputs to determine when to use tools versus generative responses. This helps avoid tool hallucinations by ensuring the system only attempts generative answers when appropriate.
- Local Processing: Their ability to run locally with low latency means they can perform real-time verification without the cost and latency of calling cloud APIs repeatedly, enabling more verification checks throughout the process.
- Specialized Domain Knowledge: Smaller models can be fine-tuned on specific domains, making them more accurate within their specialization than general-purpose large models trying to cover all knowledge areas.
In the agentic architecture, these smaller models work alongside larger models in a division of labor: larger models handle complex generation tasks, while smaller models handle verification, planning, and specialized tasks—creating a more robust system for managing hallucinations than either approach alone.
The Agentic Architecture Solution
Rather than attempting to solve hallucinations entirely at training time, modern architectures handle them through layered agent design. This approach treats hallucination as a runtime problem to be managed dynamically, similar to how fault-tolerant operating systems handle unpredictable failures.
The goal of this system is to manage and reduce hallucinations from LLMs by using an agentic framework that breaks tasks into planning, tool-assisted execution, verification via critics, and iterative feedback loops. The following diagram illustrates how these elements work together in a cohesive architecture:
System Architecture Diagram
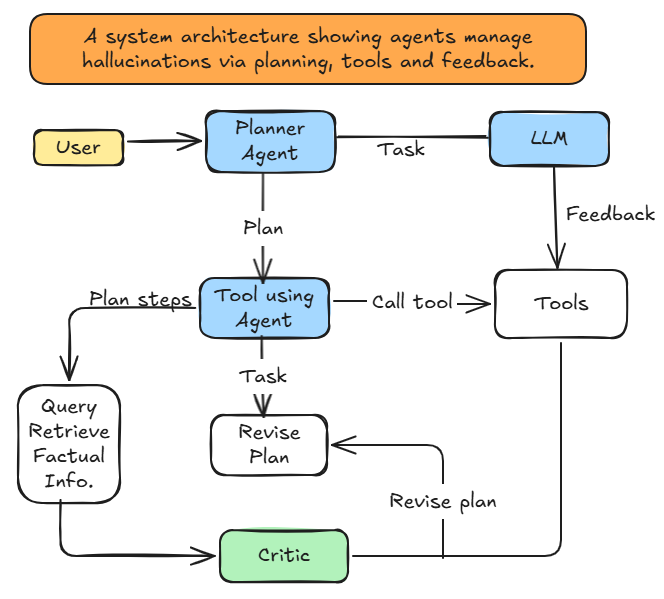
Figure 1: System architecture showing how agents manage hallucinations through planning, tool usage, and feedback mechanisms.
The diagram illustrates the key components and relationships in an agentic system designed to reduce hallucinations. User queries flow through a Planner Agent, which coordinates with the LLM and Tool-using Agent. The system incorporates multiple feedback loops and verification mechanisms to ensure factual accuracy and prevent hallucinations.
System Components
The agentic approach to hallucination reduction involves several key components working together, as shown in Figure 1:
- User:
- The entry point for the system
- Initiates the process by asking a question or issuing a task
- Example: "Generate a Q1 2025 sales report and email it to the CFO."
- Planner Agent:
- Analyzes the user request and creates a high-level plan
- Orchestrates the workflow
- Breaks down user queries into structured steps (e.g., retrieve data → format report → send email)
- Sends "Task" to the LLM for understanding if needed
- Outputs a "Plan" to the Tool-using Agent
- LLM:
- Provides core language processing capabilities
- Assists the Planner Agent with understanding or refining instructions
- Used as a reasoning engine, not a monolith
- Gives feedback based on plan outcomes if needed
- Tool-using Agent:
- Executes plans from the Planner Agent
- Calls tools as needed to complete tasks
- Responsible for issuing tool calls and sending tasks to submodules
- Manages the execution of plan steps through the Query component
- Query Component:
- Retrieves factual information to ground responses
- Often uses RAG (retrieval-augmented generation), search APIs, or vector DBs
- Ensures the LLM doesn't hallucinate or guess facts
- Acts as a fact-checking mechanism
- Tools:
- Provide deterministic functions to replace generative guessing
- Represent real-world actions: databases, report generators, email APIs, etc.
- The Tool-using Agent directly interacts with this layer
- The feedback loop from Tools informs whether the task succeeded or failed
- Critic:
- Verifies outputs and catches hallucinations
- Functions as the hallucination validator
- Verifies if the plan is logically sound
- Checks for unsupported claims or contradictions
- Scans output format/schema
- If an issue is found, sends the task back to Revise Plan for correction
- Revise Plan Component:
- Adapts plans based on feedback and verification
- When a plan step is incomplete, fails, or needs adaptation
- Outputs a revised plan for the Tool-using Agent or re-routes it back to the Planner Agent
Key Relationships and Flows
The architecture establishes several critical relationships and information flows, which can be traced in the system diagram (Figure 1):
- Primary Flow:
- User → Planner Agent → LLM: Initial task formulation
- Planner Agent → Tool-using Agent: Plan execution
- Tool-using Agent → Query/Tools: Factual grounding and tool usage
- Query/Tools → Critic: Verification
- Critic → Revise plan: Adaptation based on verification
- Revise plan → Tool-using Agent: Feedback loop for improvement
- Feedback Loops:
- Planning Loop: Planner Agent ↔ LLM
- Execution Loop: Tool-using Agent ↔ Tools
- Verification Loop: Query → Critic → Revise plan → Tool-using Agent
- Adaptation Loop: Tools → Critic → Revise plan
Here's how the feedback works in practice:
- Plan generated → executed via tools
- If execution fails (bad data, hallucinated structure):
- Tools → Feedback → Revise Plan
- If reasoning seems flawed:
- Critic → Revise Plan → re-plan
Hallucination Reduction Mechanisms
The agentic architecture implements several mechanisms to reduce hallucinations:
- Planner Agents:
- Break down user queries into manageable steps
- Ask clarifying questions when details are missing
- Prevent acting on ambiguous instructions (early hallucination defense)
- Tool-using Agents:
- Use calculators, databases, APIs, or search tools to answer questions
- Offload facts and numbers to deterministic functions, not generative guessing
- Ground responses in external, verifiable sources
- Verifier or Critic Agents:
- Rerun answers through a second model or rule-based checker
- Reject answers with contradictions, incorrect formats, or hallucinated content
- Provide feedback for plan revision
- Memory / Retrieval Layers:
- Add grounding via retrieved documents, prior messages, or citations
- Prevent hallucinated context drift across sessions
- Maintain consistency in long-running interactions
Key features of this architecture include:
- Modular Agents: Break down responsibilities for clarity and safety
- Hallucination Isolation: Critic + query agents catch hallucinated outputs
- Dynamic Planning: Revises tasks when incomplete or incorrect
- Tool Grounding: Uses APIs instead of relying on LLM speculation
- Feedback Driven: Error correction is built-in, not after-the-fact
Real-World Use Case Flow
To illustrate how this architecture works in practice, consider this example that follows the flow depicted in Figure 1:User: "Generate the finance report for FY24 and send it to CFO."
- Planner Agent: Detects intent, plans steps.
- Tool-using Agent:
- Queries database for FY24 data
- Fetches report template from SharePoint
- Generates report
- Critic:
- Reviews the report content
- Flags if numbers are inconsistent or sections are missing
- Revise Plan:
- Requests missing CFO email address
- Fixes any structure issues in the report
- Tool:
- Sends the final report via email
This example demonstrates how the system handles a complex task while preventing hallucinations through verification and feedback loops, as illustrated in the system architecture diagram.
Layer-Specific Hallucination Management
Handling Strategy by Layer
Different types of hallucinations are best handled at different layers of the system:
- Retrieval (RAG) Layer:
- Mitigates factual and speculative hallucinations
- Brings grounded facts into context
- Tool Layer:
- Executes calculations, database queries, and code
- Replaces LLM speculation with deterministic results
- Handles numerical hallucinations and tool hallucinations
- Planner Agent Layer:
- Ensures logical consistency across steps
- Catches omissions and contradictions
- Maintains focus on the original task
- Critic/Verifier Agent Layer:
- Validates outputs post-generation
- Checks for coherence, factuality, and format
- Identifies source attribution hallucinations
- Memory Layer:
- Tracks context across sessions and steps
- Prevents contradictions and context drift
- Maintains consistency in long interactions
- Prompting/Scaffolding Layer:
- Limits model creativity where undesired
- Enforces structure (e.g., JSON mode, system messages)
- Reduces format hallucinations
- Validator Functions Layer:
- Enforces schemas
- Detects format issues early
- Implements retry mechanisms on error
The CPU/OS Analogy
A helpful analogy for understanding this approach is to compare:
- LLM ≈ CPU
- Agents ≈ OS
Just as you wouldn't expect a CPU to tell you whether a program output is logically valid, you shouldn't expect a model alone to validate a financial report it just generated. Instead, you build:
- A program that handles edge cases
- An agent that uses tools and memory to validate or retry
Industry Trends
Application-Layer Hallucination Management
The industry is increasingly shifting hallucination control to the agent layer rather than relying solely on LLM training. This trend recognizes several key insights:
- LLMs as Prediction Engines: They predict probable tokens, not factual ones
- Training-time Alignment Limits: SFT + RLHF reduces tone-based hallucination but not factual ones
- Real-world Grounding: Agentic systems introduce tool usage, self-verification, planning, and external memory
This approach allows for intercepting or preventing hallucinations by grounding model outputs in:
- Trusted sources
- Deterministic functions
- Fact-checking loops
The industry is developing a layered approach:
- LLM layer: Generates text based on training (e.g., GPT-4o, Claude 3, Mistral)
- Agent layer: Plans, verifies, re-asks, grounds (e.g., LangChain, LangGraph, CrewAI)
- Retrieval layer: Brings factual knowledge into context (e.g., RAG, vector DBs, semantic search)
- Critic layer: Evaluates hallucination risk (e.g., Verifier models, contrastive reranking)
- Tool layer: Uses APIs to fetch or calculate (e.g., Search, DB query, code execution)
Where Training Still Matters
While the agentic approach shifts much of the hallucination management to the application layer, training still plays an important role:
- Reducing Frequency: Better training can reduce how often hallucinations occur
- Aligning Tone and Style: Training helps ensure lies sound less confident
- Improving Instruction-Following: Better training helps models stick to the user's question
However, training alone will never eliminate hallucinations because models fundamentally lack access to truth—they only have access to probabilities.
Conclusion
The Future of Hallucination Control
Hallucinations won't disappear with the next generation of language models. In fact, as models get better at language, hallucinations may become harder to spot. The sustainable solution is to treat LLMs as one piece of a larger system and build agentic architectures that reason, validate, and ground outputs in real data.The future of hallucination control doesn't belong to training alone—it belongs to agent orchestration. This approach treats hallucination like software failure: different types represent different failure modes, requiring different modules responsible for catching and correcting them.
Implications for AI Development
Instead of hoping for hallucination-free LLMs, the industry is building structured agent systems that detect, prevent, or recover from failure, just like modern operating systems do for hardware and software errors. This shift represents a fundamental change in how we approach AI reliability, moving from model-centric to system-centric thinking.
By embracing this agentic approach, developers can build more reliable, trustworthy AI applications that leverage the strengths of LLMs while systematically addressing their limitations. The architectural principles of separation of concerns, verification at multiple levels, adaptive planning, tool augmentation, and feedback-driven improvement provide a robust framework for managing hallucinations in practical applications.