Reflection: Should Tokenizers Be Standardized?

In natural language processing, tokenization is often viewed as a preprocessing detail — a mechanical step that converts text into token IDs. But after exploring models like GPT-4o and BERT, I’ve come to see tokenization as something far more foundational: it’s the assembly language of AI.
⚙️ The Processor Architecture Analogy
To understand why tokenization matters so deeply, consider this analogy: each embedding model (BERT, GPT, T5, etc.) functions essentially as its own processor architecture:
| NLP Concept | Processor Analogy |
|---|---|
| Embedding model | A processor (e.g., x86, ARM, RISC-V) |
| Tokenizer | The model's assembler |
| Token IDs | The machine code / binary |
| Embedding vectors | The binary executed by the processor |
[CLS], [SEP] |
Special instruction codes |

This analogy illuminates several critical insights:
- You can't mix binaries across architectures, just as you can't mix token IDs across models
- The assembler is tightly coupled to the CPU instruction set, just as a tokenizer is bound to its model's vocabulary
- The same code (intent) produces different binaries on different architectures, just as the same sentence yields different token IDs across models
- There is no universal binary standard, just as there is no universal embedding/token standard
❓ The Standardization Question
What caught my attention was how even Open AI uses different tokenizers across their own model generations—GPT-3, GPT-3.5/4, and GPT-4o each employ distinct tokenization schemes. This isn't just a backend technicality. Each model is trained specifically to interpret the tokens produced by its tokenizer. Even a slight change in tokenizer means retraining or re-engineering the model — because token IDs, vocabulary, and attention patterns are all tightly coupled.
This tight coupling creates a fundamental challenge: if we want more modular, interoperable AI systems, why isn't there a standardized approach to tokenization?
📊 Tokenizer Comparison Chart
| Tokenizer | Used By | Granularity | Language Support | Notes |
|---|---|---|---|---|
| WordPiece | BERT, DistilBERT, ALBERT | Subword | Mostly English | Requires vocab.txt |
| BPE (Byte Pair Encoding) | GPT-2, GPT-J | Subword | Multilingual | Merges common byte pairs |
| SentencePiece | T5, ALBERT, mT5, XLM-R | Subword | Multilingual | Good for low-resource/multilingual models |
| Byte-level BPE | GPT-3.5, GPT-4, GPT-4o, Claude | Byte/Subword | Multilingual | Robust across domains |
| Character-level | CharBERT, legacy models | Character | Language-agnostic | Rarely used; long sequences |
| OpenNMT Tokenizer | OpenNMT models | Configurable | Multilingual | Supports BPE/SentencePiece |
Tiktoken (cl100k_base) |
OpenAI GPT-3.5/4/4o | Byte-level BPE | Multilingual | Optimized for speed + token accounting |
🧩 The MoE Architecture Insight
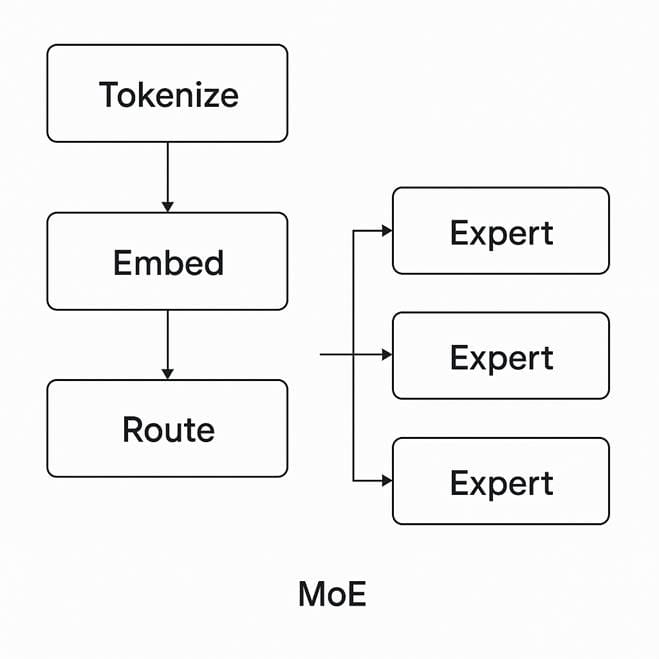
Initially, I wondered if Mixture of Experts (MoE) architectures—which are gaining momentum for scaling efficient language models—might benefit from specialized tokenizers for different domains. After all, if experts specialize in code, law, or casual conversation, wouldn't domain-specific tokenization make sense?
But deeper research revealed an important technical reality: tokenization in MoE models happens once, before routing, and all experts operate on shared embeddings or hidden states. Routing occurs within the model based on token-level or layer-level activations—not on separate token streams. This architecture constraint actually reinforces the need for tokenizer consistency.
☕ Toward a "Write Once, Run Anywhere" Tokenization
What the NLP field needs isn't necessarily one universal tokenizer, but rather something akin to what Java achieved for programming: a "write once, run anywhere" approach. Just as Java uses the JVM to abstract away hardware differences, we need an intermediate representation layer for tokenization that could bridge different model architectures.
Efforts Moving in This Direction:
Tokenizer Libraries:
- Hugging Face Tokenizers: Unified API across tokenization schemes
- OpenNMT Tokenizer: Fast BPE/SentencePiece implementation in C++/Python
- Stanford Tokenizer: Rule-based, language-aware (CoreNLP)
Model Trends:
- Byte-level BPE: Adopted by GPT-4o, Claude, and other multilingual models
What We Might Need:
- A standardized intermediate token representation
- Compatibility protocols between tokenization schemes
- A universal base vocabulary with domain-specific extensions
- Model architectures that tolerate tokenization variation
Without standardization, model families become increasingly siloed — making interoperability, transfer learning, and efficient deployment across tasks unnecessarily difficult.
Without standardization, model families become increasingly siloed — making interoperability, transfer learning, and efficient deployment across tasks unnecessarily difficult.
🚀 The Path Forward
Standardizing tokenization—not into one global system, but into a small set of robust, shared approaches—could benefit the entire AI ecosystem. It would allow different models to align on input formats, support better transfer learning, and simplify downstream processing across model families.
Just as UTF-8 standardized how we encode characters, a well-agreed-upon set of tokenization formats could dramatically reduce friction in training, deploying, and integrating language models. The academic community, which has driven so much of LLM development, is well-positioned to lead this standardization effort.
Tokenization isn't just about breaking words into parts—it's about defining the very interface between language and computation. Getting it right—and consistent—could be a quiet revolution in how AI systems collaborate, scale, and evolve. The question isn't whether we need tokenizer standardization, but how quickly we can achieve it.