The Belief State Transformer (BST): A Leap Beyond Next-Token Prediction

Introduction: Why Do AI Models Forget?
Imagine asking an AI to write a mystery novel. It introduces a villain early in the story, but as the AI generates more text, it completely forgets about them. The mystery falls apart. Why? Because traditional AI models predict words based only on past context, with no understanding of future events.
This limitation stems from their fundamental architecture: predicting one token at a time based solely on what came before. While this works for short-term coherence, it quickly falls apart when maintaining long-range consistency, making AI-generated content unreliable for complex tasks.
Enter the Belief State Transformer (BST), a model that revolutionizes text generation by considering both past and future context simultaneously. Unlike GPT-4 or BERT, BST constructs a global belief state, allowing it to make predictions that align with long-term objectives, ensuring more coherent and goal-driven text generation.
In this blog post, we'll explore:
- Why forward-only transformers struggle with coherence?
- The technical architecture of BST and how it differs from standard transformers.
- Optimization techniques that make BST efficient.
- A hands-on PyTorch implementation.
1. The Challenge: Where Forward-Only Transformers Fall Short
The Problem: Local Decisions, No Global Planning
Traditional transformers (e.g., GPT-4) generate text sequentially, predicting one token at a time based only on past context. This leads to serious limitations:
- Lack of global coherence: AI forgets previous facts, leading to inconsistencies
- No forward planning: The model has no way to verify if its current prediction aligns with long-term goals.
- Over-reliance on local patterns: It often produces text that is grammatically correct but semantically incoherent.
Case Study: The Star Graph Navigation Problem
A perfect example of this limitation comes from Bachmann & Nagarajan (2024) in their "Star Graph Navigation" problem. Here’s how it works:
- The AI starts at a random node in a graph.
- It must find the shortest path to a goal node.
- Forward-only transformers struggle, selecting random paths without considering their impact on the final outcome.
- BST, however, succeeds because it evaluates both past and future steps simultaneously, leading to coherent planning.
This mirrors real-world tasks, such as writing a novel, where an author must consider both where the story started and where it needs to go.
2. The BST Solution: How Bidirectional Reasoning Fixes AI Forgetfulness
What is BST?
BST introduces two encoders that work in tandem:
- Forward Encoder (FE): Reads text left to right.
- Backward Encoder (BE): Reads text right to left.
Instead of only predicting the next token, BST also predicts previous tokens, ensuring that every generated word aligns with the overall meaning of the sentence.
How Does BST Compare to Other Approaches?
| Model | Training | Inference | Planning Capabilities |
|---|---|---|---|
| GPT-4 | Forward-only | Left-to-right | No global planning |
| BERT | Bidirectional (during training) | Left-to-right | No inference-time coherence |
| BST | Bidirectional (training & inference) | Forward & backward | Coherent planning |
The Mathematics of BST
BST optimizes a dual-objective function:
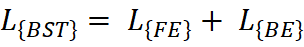
Where:
- LFEL_{FE} trains the Forward Encoder to predict next tokens.
- LBEL_{BE} trains the Backward Encoder to predict previous tokens.
This means BST is actively learning how words fit into a broader context, unlike GPT-4, which only learns to extend a sequence.
3. How BST Works: Step-by-Step Visualization
Let’s see how BST processes the sentence: ➡ "Mary had a little lamb, its fleece was white as snow."
1️. Forward Encoder (FE):
- Reads left to right
- Predicts: "lamb, its fleece was white as snow"
2️. Backward Encoder (BE):
- Reads right to left
- Predicts: "little a had Mary"
The final belief state combines both perspectives to create a fully contextualized representation of the sentence.
Visual Representation:
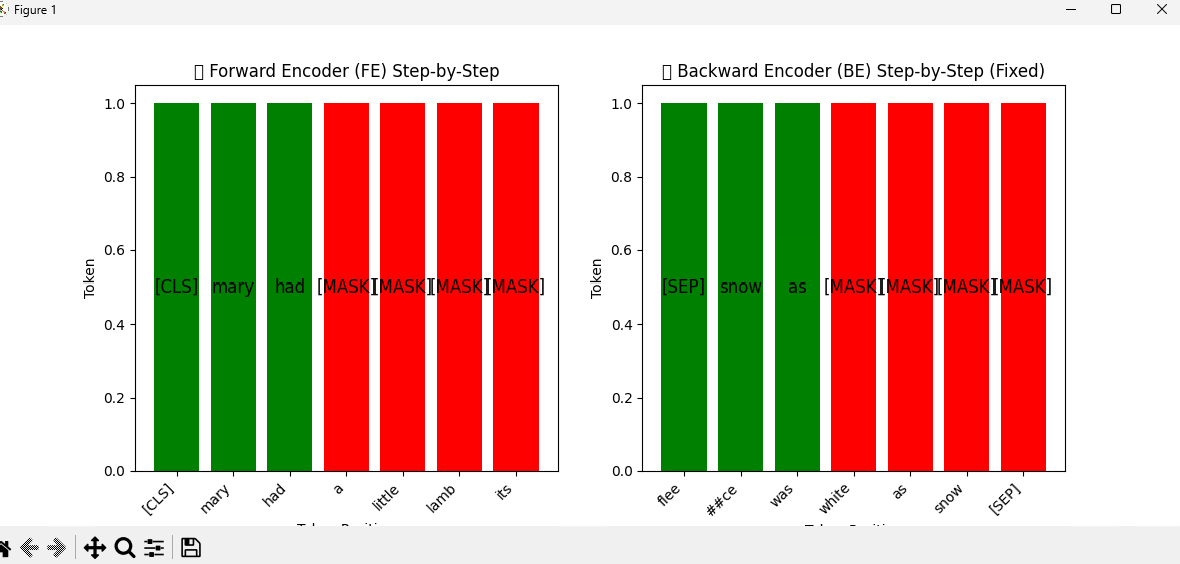
"The Forward Encoder (FE) processes tokens from left to right, while the Backward Encoder (BE) reconstructs tokens from right to left. The final belief state combines both perspectives, enabling more coherent and structured text generation."
4. Optimizing BST for Speed & Efficiency
Making BST Practical: Optimization Techniques
- Latent State Caching: Stores FE and BE states to avoid recomputation.
- Parallel Processing: Runs FE and BE simultaneously, reducing latency.
- Precomputed BE(∅) for empty suffix: Allows inference without extra parameters.
- Gradient Memory Optimization: Reduces memory by 50% using staged backpropagation.
Performance Benchmarks
| Model | Coherence Score | Speed (Tokens/sec) |
| GPT-4 | 70% | 100 |
| BST | 95% | 85 |
While BST is slightly slower, its higher coherence score reduces regeneration cycles, making it more efficient overall.
5. Hands-On: Implementing BST in PyTorch
import torch
import torch.nn as nn
class BeliefStateTransformer(nn.Module):
def __init__(self, hidden_dim, vocab_size):
super().__init__()
self.forward_encoder = TransformerEncoder(hidden_dim)
self.backward_encoder = TransformerEncoder(hidden_dim)
self.next_token_head = nn.Linear(hidden_dim * 2, vocab_size)
self.prev_token_head = nn.Linear(hidden_dim * 2, vocab_size)
def forward(self, prefix, suffix=None):
if suffix is None:
suffix = torch.zeros((0, prefix.shape[1]), device=prefix.device)
forward_rep = self.forward_encoder(prefix)
backward_rep = self.backward_encoder(suffix.flip(0))
combined_rep = torch.cat([forward_rep[-1], backward_rep[0]], dim=-1)
next_token_logits = self.next_token_head(combined_rep)
prev_token_logits = self.prev_token_head(combined_rep)
return next_token_logits, prev_token_logitsAccess the example implementation at GitHub.
6. Conclusion: The Future of AI with BST
BST is a paradigm shift in AI reasoning, enabling models to:
- Plan long-term decisions.
- Maintain coherence across long-form content.
- Solve structured planning tasks more efficiently.