Understanding Machine Learning Pipelines: From Data to Deployment
You'll often hear data scientists and machine learning practitioners talk about pipelines or lifecycles — and for good reason. In data science, a pipeline is a structured, automated process that transforms raw data into actionable insights. It encompasses everything from data collection and cleaning to analysis, model training, and deployment.
🚀 Why Do We Need a Model Training Pipeline?
Building a well-defined ML pipeline provides benefits beyond just structure:
- Efficiency: Automates repetitive tasks, reducing manual overhead.
- Consistency: Ensures repeatable results across development and production.
- Modularity: Allows easy swapping of components (e.g., changing models or features).
- Experimentation: Simplifies model tracking and comparison.
- Scalability: Supports larger datasets and evolving requirements.
There are many pipelines in practice — each tailored to a slightly different workflow. Some of the most recognized include:
CRISP-DM (Cross Industry Standard Process for Data Mining)
The Cross-Industry Standard Process for Data Mining (CRISP-DM) remains one of the most widely adopted frameworks in the data science community since its introduction in the late 1990s. Its enduring popularity stems from its comprehensive, iterative approach that emphasizes business alignment throughout the entire process.
CRISP-DM consists of six interconnected phases: Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, and Deployment. What makes this methodology particularly powerful is how it places ground truth validation at critical junctures in the process.
During the Data Understanding phase, CRISP-DM emphasizes thorough exploration of available data, including the verification of ground truth labels. This early focus ensures that subsequent modeling efforts are built on a solid foundation. For instance, in a sentiment analysis project using the BERT model (similar to our complexity classification example), CRISP-DM would guide practitioners to carefully examine the labeled tweets, verify their accuracy, and ensure balanced representation before proceeding to model development.
The iterative nature of CRISP-DM also provides multiple opportunities to refine ground truth. After initial modeling, the Evaluation phase prompts practitioners to assess model performance against business objectives, often leading to a reassessment of the ground truth itself. This cyclical approach acknowledges that ground truth may evolve as business understanding deepens.
PBTD (Prepare, Build, Train, Deploy)
The Prepare, Build, Train, Deploy (PBTD) methodology offers a streamlined approach particularly well-suited for beginners and small teams looking for a clear, linear path through the machine learning lifecycle. While simpler than some alternatives, PBTD doesn't compromise on the importance of ground truth.
In the Prepare phase, PBTD places significant emphasis on establishing reliable ground truth early in the process. This involves not just collecting and cleaning data, but explicitly labeling it to create the foundation for model training. The BERT complexity classification notebook exemplifies this approach perfectly in Step 3, where labeled training and test data are loaded with clear complexity categories ("simple," "medium," "complex") serving as ground truth.
The Build and Train phases then leverage this established ground truth, with the Train phase specifically measuring model performance against these verified labels. In our BERT example, Step 9 (Evaluate) demonstrates this by comparing model predictions against the ground truth labels using classification reports and confusion matrices.
PBTD's straightforward nature makes it accessible for teams new to machine learning, while still maintaining the critical focus on ground truth that ensures model reliability.
OODA Loop (Observe, Orient, Decide, Act)
The Observe, Orient, Decide, Act (OODA) Loop, originally developed as a military strategy framework, has found valuable applications in machine learning systems that require rapid adaptation to changing conditions. This methodology is particularly well-suited for real-time, adaptive systems where decision-making speed is critical.
The OODA Loop's approach to ground truth is distinctive in its emphasis on continuous observation and reorientation. In the Observe phase, systems actively gather new data that may influence or update ground truth. The Orient phase then contextualizes these observations against existing knowledge, potentially adjusting ground truth understanding based on new information.
This adaptive approach to ground truth makes OODA particularly valuable for applications in dynamic environments. For instance, in a real-time implementation of our BERT complexity classifier for routing customer queries, an OODA approach would continuously monitor incoming queries and human agent interventions, using this feedback to adapt ground truth labels as new patterns emerge.
The methodology's focus on rapid cycles also acknowledges that perfect ground truth may not be achievable in fast-moving scenarios. Instead, OODA emphasizes making the best decisions possible with available information, then quickly incorporating feedback to improve future iterations.
MLOps (Machine Learning Operations)
Machine Learning Operations (MLOps) extends beyond traditional methodologies to address the unique challenges of operationalizing machine learning at scale. For enterprise organizations with cloud-native setups, MLOps provides a framework that emphasizes automation, monitoring, and continuous improvement throughout the machine learning lifecycle.
What distinguishes MLOps in terms of ground truth is its sophisticated approach to continuous validation. Rather than treating ground truth as static, MLOps implements feedback loops that constantly evaluate and potentially update ground truth based on real-world performance. This is particularly valuable in dynamic environments where data distributions may shift over time.
MLOps incorporates automated monitoring systems that track model performance against established ground truth, triggering alerts when significant deviations occur. For example, in a production deployment of our BERT complexity classifier, an MLOps approach would continuously compare model predictions against human-verified samples, potentially flagging the need for model retraining if accuracy drops below a threshold.
The methodology also emphasizes version control not just for code and models, but for datasets and ground truth labels as well. This ensures reproducibility and provides an audit trail for how ground truth evolves throughout a model's lifecycle.
TDSP (Team Data Science Process)
Microsoft's Team Data Science Process (TDSP) combines elements of Agile methodology with data science best practices to create a framework particularly well-suited for collaborative teams. TDSP's structured approach to project management and documentation makes it especially valuable for organizations where multiple stakeholders contribute to machine learning initiatives.
TDSP places special emphasis on the collaborative aspects of establishing ground truth. The methodology includes specific roles and responsibilities for data scientists, data engineers, and domain experts, recognizing that ground truth often requires input from various perspectives. For instance, in a medical diagnosis application using BERT, TDSP would formalize the process by which clinicians (domain experts) validate the labeled training data before model development begins.
The methodology also provides standardized templates for documenting ground truth sources, labeling procedures, and quality assurance processes. This documentation ensures transparency and facilitates knowledge transfer across team members. In our BERT example, TDSP would encourage detailed documentation of how the complexity labels were assigned, who verified them, and what criteria were used.
KDD (Knowledge Discovery in Databases)
The Knowledge Discovery in Databases (KDD) process represents one of the earliest formalized approaches to extracting insights from data. Developed primarily in academic settings, KDD provides a systematic framework for exploratory data analysis with a strong emphasis on discovering valid, novel, potentially useful, and ultimately understandable patterns.
KDD's approach to ground truth is particularly thorough in its validation requirements. The process includes explicit steps for assessing the statistical significance of discovered patterns against established ground truth. This academic rigor makes KDD well-suited for research applications where the validity of findings must meet stringent criteria.
The methodology also acknowledges the iterative nature of ground truth refinement. As new patterns are discovered, KDD encourages researchers to revisit and potentially revise their understanding of ground truth. For example, in analyzing our BERT complexity classification results, a KDD approach might prompt further investigation into misclassified examples, potentially leading to refined ground truth labels for future iterations.
Methodology Comparison: Finding Your Path
Regardless of which methodology you follow, they all aim to bring clarity, reproducibility, and scalability to the machine learning process.
Summary Table: Machine Learning Methodologies
| Pipeline Name | Best For | Focus On | Relation to Ground Truth |
|---|---|---|---|
| PBTD | Beginners, small teams | Clean path from data to deployment | Emphasizes data preparation where ground truth is established early in the process |
| CRISP-DM | Industry-standard, flexible | Business alignment + iteration | Incorporates data understanding phase where ground truth validation is critical |
| MLOps | Enterprise ML, cloud-native setups | Monitoring, automation, scaling | Continuous validation of ground truth through monitoring and feedback loops |
| TDSP | Collaborative teams | Project management + collaboration | Structured approach to data acquisition and labeling for ground truth |
| KDD | Academic, exploratory data analysis | Knowledge discovery from data | Focuses on pattern discovery where ground truth serves as validation |
| OODA | Real-time, adaptive systems | Continuous decision-making | Observation phase heavily relies on accurate ground truth for decision quality |
When selecting a methodology for your machine learning projects, consider how each approach handles ground truth in relation to your specific requirements:
- If you need a comprehensive, business-aligned approach with multiple validation points, CRISP-DM offers a proven framework.
- For beginners seeking a clear, straightforward path with early ground truth establishment, PBTD provides an accessible entry point.
- Enterprise organizations requiring sophisticated monitoring and continuous validation should consider MLOps.
- Teams with multiple stakeholders who need collaborative ground truth development will benefit from TDSP's structured approach.
- Research projects demanding rigorous validation of discovered patterns are well-served by KDD.
- Applications in dynamic environments requiring rapid adaptation should explore the OODA Loop's flexible approach to ground truth.
Any of these pipelines, when visualized, resemble a directed acyclic graph (DAG) — where data flows from ingestion to inference in clearly defined, non-repeating steps.
Typical stages include:
- Data Ingestion
- Data Preprocessing
- Feature Engineering
- Model Training
- Model Validation
- Hyperparameter Tuning
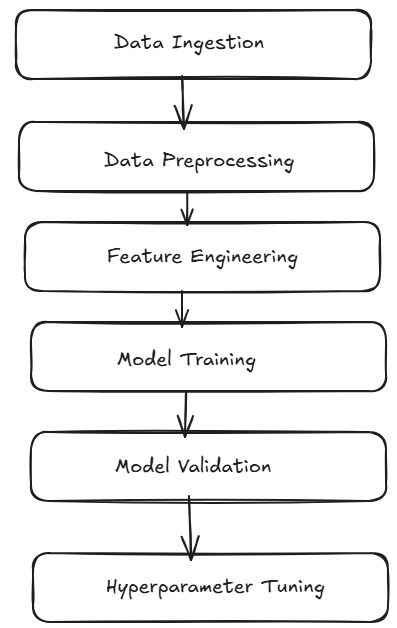
Each of these steps plays a vital role, but none of them matter if you don't know what the "right" answer looks like.
🎯 Ground Truth: The Bedrock of Machine Learning
At the heart of every successful machine learning model lies one fundamental component: ground truth.
Ground truth refers to the true, verified labels or outcomes in your dataset. It serves as the standard of correctness your model aims to learn and later be evaluated against.
Without it, your model is essentially guessing without ever knowing if it's right or wrong.
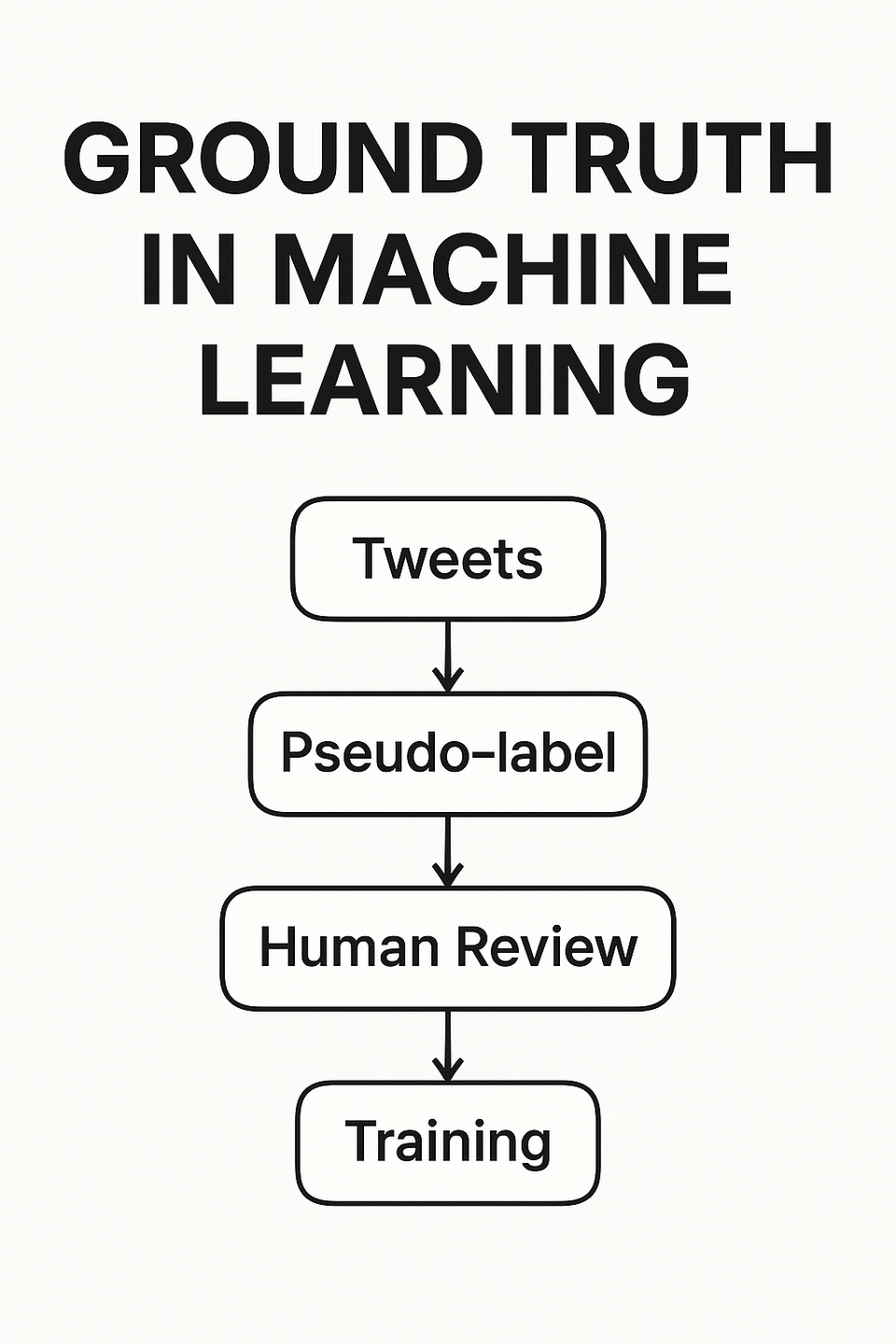
🧵 Example: Sentiment Analysis of Tweets
Let's say your company wants to analyze customer sentiment using your Twitter feed. You have a dataset full of tweets — great! But here's the problem:
None of them are labeled as Positive, Negative, or Neutral.
This is where ground truth becomes critical. Without labeled examples, your model has no reference point for learning. It's like trying to teach someone to recognize emotions without ever telling them what "happy" or "angry" looks like.
So how do you get to a point where ground truth exists?
🔄 Creating Ground Truth When You Don't Have It
Here are some practical ways to create or approximate ground truth:
✅ 1. Manual Labeling
The most reliable approach. Select a sample of tweets and label them by hand (or use tools like Amazon SageMaker Ground Truth, Label Studio, or spreadsheets). This small dataset can then be used to train or validate your model.
⚙️ 2. Heuristic Labeling
Write basic rules or keyword matchers. For example:
Tweets with words like "love", "awesome", or "😊" might be labeled Positive.
Words like "hate", "worst", or "😡" suggest Negative.
This works as a quick way to bootstrap labels, though it's prone to noise and bias.
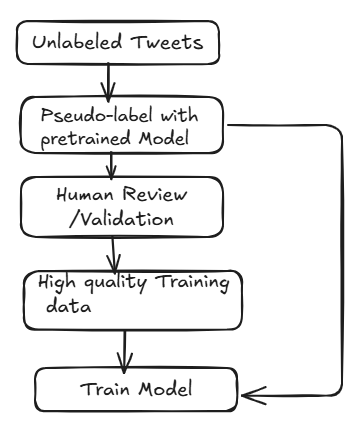
🧠 3. Pretrained Models (Pseudo-labeling)
Use sentiment analysis tools like VADER, TextBlob, or transformer-based models from HuggingFace to generate initial labels. These may not be perfect but are often "good enough" to start.
🔁 4. Human-in-the-Loop / Active Learning
Let the model label most data, and have humans validate or correct a small, uncertain subset. This is efficient and improves your dataset quality over time.
📦 Ground Truth Throughout the Pipeline
Once you have reliable labels:
- Your training stage knows what it's optimizing for.
- Your validation stage can accurately measure model performance.
- Your deployment stage can be monitored by comparing predictions with future ground truth (if feedback is available).
In short:
Ground truth is not just a component — it's the compass your entire pipeline depends on.
Practical Implementation: BERT Training Example
The BERT training notebook for complexity classification provides an excellent practical example of how these methodologies manifest in real-world machine learning development. The notebook follows a structured approach that incorporates elements from several methodologies:
- Ground Truth Establishment: In Step 3, the notebook loads labeled training and test data with clear complexity categories ("simple," "medium," "complex") serving as ground truth.
- Label Encoding: Step 4 encodes these categorical labels into numerical format, preserving the ground truth information in a form suitable for model training.
- Model Training Against Ground Truth: Steps 5-8 involve preparing the model architecture and training it against the established ground truth labels.
- Evaluation Against Ground Truth: Step 9 evaluates model performance by comparing predictions against ground truth labels, using classification reports and confusion matrices to assess accuracy.
This example demonstrates how ground truth serves as the foundation throughout the entire machine learning process, regardless of which specific methodology is followed. The labeled data provides the standard against which the model is trained, evaluated, and ultimately judged for deployment readiness.
⚠️ Common Pitfalls in Ground Truth Labeling
-
Assuming labels are always correct
Even high-quality labels can contain noise due to human error or subjectivity. -
Reusing old labels without revalidation
Data and context can evolve — what was correct 2 years ago may no longer be valid. -
Imbalanced labels leading to biased models
If one class dominates (e.g., 90% “neutral” tweets), models may learn to predict that for everything. -
Lack of domain expertise during labeling
Especially in specialized fields (e.g., medicine, law), ground truth created by non-experts can mislead training. -
Labeling based on incomplete context
A tweet may appear negative unless you know the backstory or cultural reference — missing context can lead to mislabeling.
💡 Ground Truth ≠ Perfect Truth
In real-world machine learning, ground truth does not always equal absolute truth.
Human annotators bring their own biases, assumptions, and limitations — which can introduce noise or disagreement in labels.
Even in domains like medical diagnosis or legal document classification, two experts may disagree on the same data point.
That’s why it’s often more helpful to treat ground truth as the best available approximation, not an unchangeable fact.
🧩 Mini Case Study: Label Quality Boosts Accuracy
A mid-size e-commerce company aimed to analyze customer sentiment using a BERT-based classifier trained on 10,000 tweets.
However, the model plateaued at ~72% accuracy.
Upon reviewing the ground truth, the team discovered:
- Inconsistent labeling criteria
- Heavily imbalanced label distribution
- Outdated slang and sarcasm missed by annotators
After re-labeling 1,500 tweets with clearer guidelines, balancing the dataset, and adding a few sarcastic examples,
accuracy jumped from 72% to 88% on the validation set.
This highlights that improving ground truth can sometimes yield bigger gains than hyperparameter tuning or model selection.
✨ Final Thoughts
Whether you're following CRISP-DM, PBTD, or a custom workflow, the importance of ground truth cannot be overstated. It is the standard, the teacher, and the judge of your model.
Investing in accurate, meaningful ground truth early in the process saves time, improves outcomes, and ensures your ML efforts are rooted in reality — not just guesses.
Regardless of which methodology you choose, remember that ground truth remains the compass that guides your entire machine learning journey. Investing in accurate, meaningful ground truth early in the process will pay dividends throughout development and into deployment.