Building a Cost-Efficient AI Query Router: From Fuzzy Logic to Quantized BERT
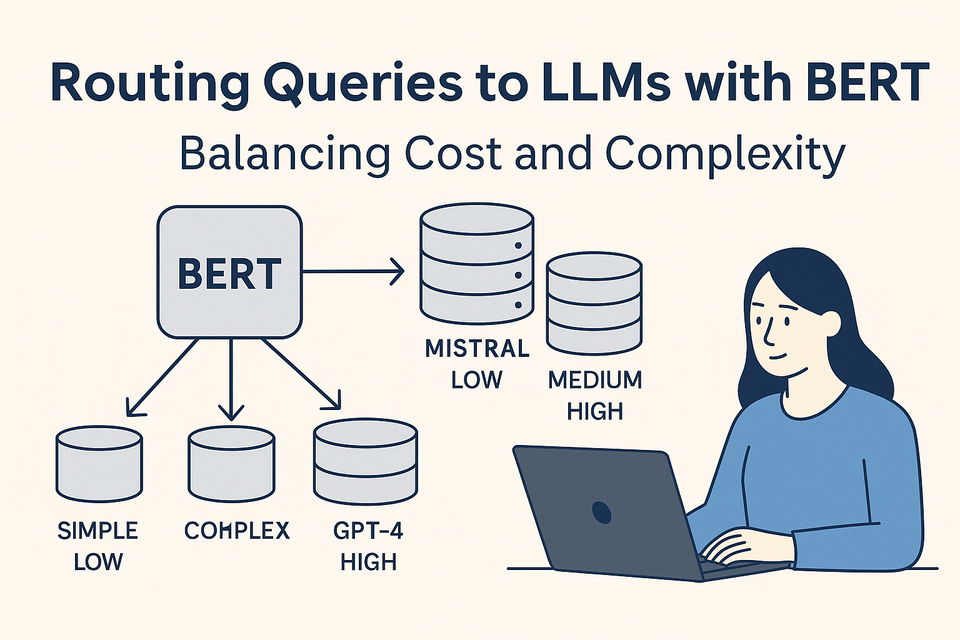
Modern AI applications often integrate large language models (LLMs) like GPT-4, Mistral, and Claude to answer user queries, automate tasks, and generate insights. However, routing every user query to a high-end LLM can be prohibitively expensive and computationally inefficient. Not every task demands the intelligence (or cost) of a 175B+ parameter model. We were faced with this very challenge: How can we intelligently route user queries to the right LLM, depending on the complexity of the task, while minimizing cost and latency?
🧠 Step-by-Step Breakdown of Our Solution
| Step | What Happens | Details |
|---|---|---|
| 1️⃣ | User query comes in | e.g., "Cancel my subscription" |
| 2️⃣ | BERT does two things | a) Classifies intent (cancel_service) b) Predicts complexity class (simple, medium, complex) |
| 3️⃣ | Router acts | Based on BERT output: - simple → Execute backend action 🔁 No LLM call, no JSON, just a handler - medium → Call Mistral-7B 🔄 Reasonable cost/perf tradeoff - complex → Call GPT-4o 🤖 Full-on reasoning |
| 4️⃣ | Log both BERT and LLM decisions for learning | For evaluation, debugging, future model fine-tuning |
Initial Attempt: Fuzzy Logic-Based Classification
Our first solution was to use a Fuzzy Logic controller. The code we initially implemented assigned complexity scores based on sentence features like keyword density, punctuation, and structure. If the score was low, the query was treated as simple and sent to a cheaper model. If the score was high, the query was forwarded to a larger model like GPT-4o. While this approach was functional, it had serious limitations:
- Heuristic-based, not learning-based — so it couldn't adapt to nuanced queries.
- Slow, as each rule had to be evaluated manually.
- Brittle in real-world scenarios — it failed on natural language subtleties.
For example, a query like: "Can you please help me schedule a meeting?"...would get a higher complexity score just because of its polite phrasing and word count. Fuzzy logic doesn't understand intent, only surface-level features. It relies heavily on predefined rules, which makes it brittle and hard to generalize. Clearly, we needed a solution that understood language semantically.
Dataset Selection for Query Classification
Before diving into model selection, we carefully evaluated several datasets to ensure our classifier would be trained on appropriate data:
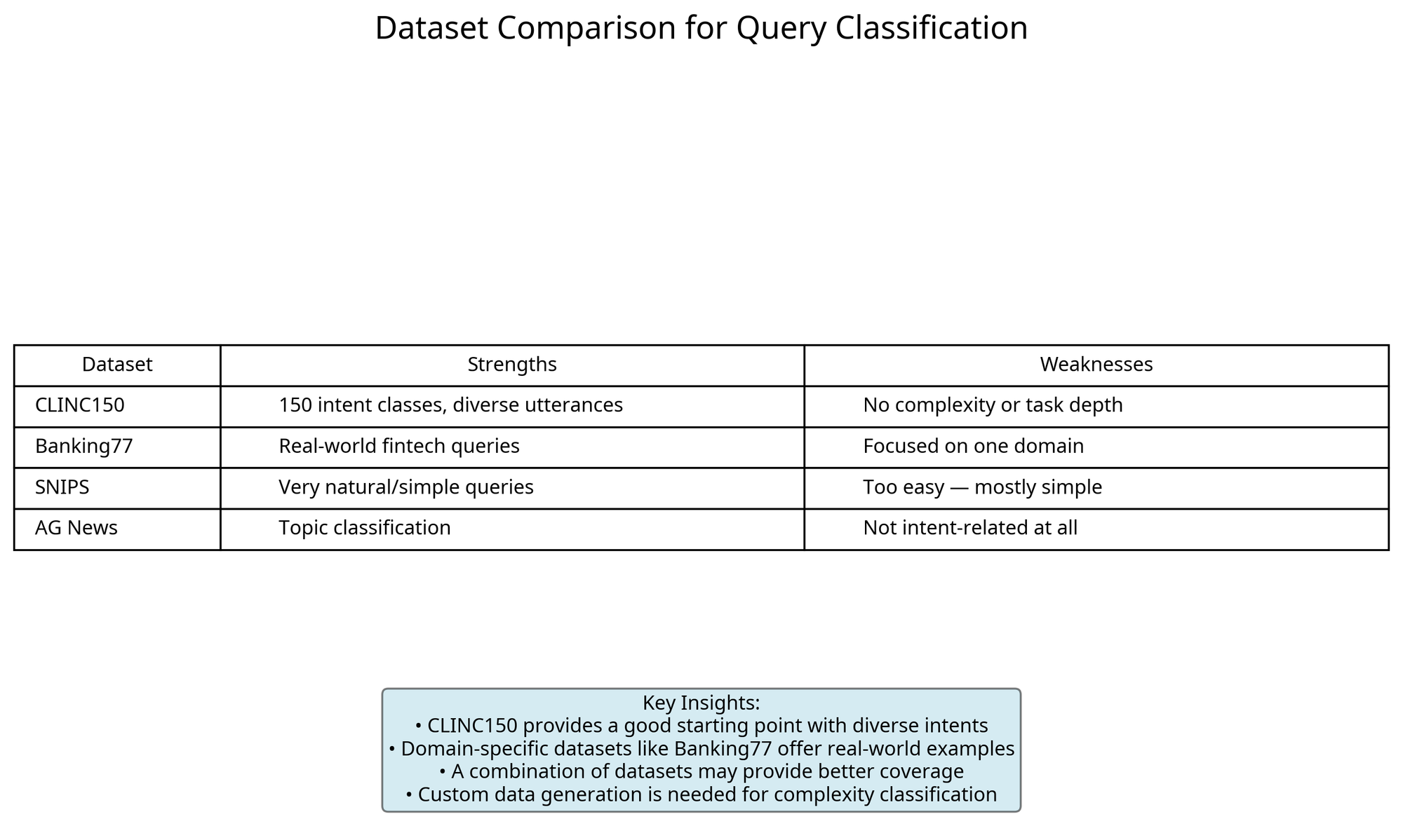
While CLINC150 provided a good starting point with its diverse intents, we found that none of the existing datasets adequately captured the complexity dimension we needed. This led us to generate synthetic datasets using prompt engineering to create examples across our three complexity categories.
Why We Chose BERT
We turned our attention to transformers and selected BERT-large-uncased for several reasons:
- Bidirectional understanding: Unlike GPT-style decoders, BERT is an encoder that understands context from both directions. This makes it perfect for classification.
- Proven track record: BERT has been widely adopted for tasks like sentiment analysis, intent detection, and text classification.
- High accuracy, even without large datasets: Fine-tuning BERT on domain-specific data yields strong performance.
- Available pre-trained weights: Easy to bootstrap and fine-tune.
Other options like DistilBERT or RoBERTa were considered, but we prioritized accuracy over size in our MVP stage.
Data Generation & Labeling
Since we didn't have production data yet (the platform is still in development), we generated synthetic datasets using prompt engineering. We created 500 labeled queries each for simple, medium, and complex classes. Here are examples of queries in each complexity category:
Simple Queries
Simple queries are straightforward requests that can be handled with basic backend actions without requiring complex reasoning or generation.
Query | Classification Reason | Routing Destination |
|---|---|---|
"What is the weather today?" | Single-intent query with no parameters beyond location (which can be inferred) | Backend API |
"Play relaxing jazz music." | Clear action with simple parameter (genre = jazz, mood = relaxing) | Backend API |
"Set an alarm for 7 AM." | Specific action with clear parameters (time = 7 AM) | Backend API |
Medium Queries
Medium queries require some reasoning, parameter extraction, or moderate generation capabilities, but don't need the full reasoning power of the largest models.
Query | Classification Reason | Routing Destination |
|---|---|---|
"Cancel my subscription effective immediately." | Requires understanding user intent, identifying the subscription, and handling a time modifier | Mistral-7B |
"Remind me to call mom when I get home tomorrow." | Multiple parameters (action, person, condition, time) requiring coordination | Mistral-7B |
"Find Italian restaurants near me with outdoor seating and good reviews." | Multiple constraints and preference ranking | Mistral-7B |
Complex Queries
Complex queries involve multiple steps, deep reasoning, creative generation, or handling ambiguous instructions that require sophisticated understanding.
Query | Classification Reason | Routing Destination |
|---|---|---|
"Email the summary report to the CFO and update the dashboard." | Multi-step process involving generation, understanding of business context, and multiple actions | GPT-4o |
"Summarize Steve's email and generate a word document report." | Complex generation task requiring understanding email content and formatting a formal document | GPT-4o |
"Research the impact of the new tax law on our investment strategy and draft a response to investors." | Deep reasoning, research synthesis, and professional writing | GPT-4o |
We split the dataset into training and test sets and trained bert-large-uncased using the Hugging Face Trainer API.
# Training code for BERT complexity classifier
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score, classification_report
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from transformers import DataCollatorWithPadding
import torch
# Load training and test data
train_df = pd.read_csv("complexity_labeled_queries.csv")
test_df = pd.read_csv("complexity_test_set.csv")
# Encode labels
label2id = {"simple": 0, "medium": 1, "complex": 2}
id2label = {v: k for k, v in label2id.items()}
train_df["label"] = train_df["complexity"].map(label2id)
test_df["label"] = test_df["complexity"].map(label2id)
# Initialize tokenizer and model
tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
model = BertForSequenceClassification.from_pretrained("bert-large-uncased", num_labels=3)
# Tokenization function
def preprocess_function(examples):
return tokenizer(examples["query"], truncation=True, padding="max_length", max_length=64)
# Prepare datasets
train_dataset = train_df[["query", "label"]].rename(columns={"query": "text"})
test_dataset = test_df[["query", "label"]].rename(columns={"query": "text"})
from datasets import Dataset
train_dataset = Dataset.from_pandas(train_dataset)
test_dataset = Dataset.from_pandas(test_dataset)
train_dataset = train_dataset.map(preprocess_function, batched=True)
test_dataset = test_dataset.map(preprocess_function, batched=True)
train_dataset.set_format(type="torch", columns=["input_ids", "attention_mask", "label"])
test_dataset.set_format(type="torch", columns=["input_ids", "attention_mask", "label"])
# Training setup
training_args = TrainingArguments(
output_dir="./bert-complexity",
evaluation_strategy="epoch",
save_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
logging_dir="./logs",
report_to="none",
load_best_model_at_end=True,
metric_for_best_model="accuracy"
)
def compute_metrics(p):
preds = np.argmax(p.predictions, axis=1)
return {"accuracy": accuracy_score(p.label_ids, preds)}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorWithPadding(tokenizer),
compute_metrics=compute_metrics
)
# Train the model
trainer.train()
# Evaluate
predictions = trainer.predict(test_dataset)
preds = np.argmax(predictions.predictions, axis=1)
print("Classification Report:")
print(classification_report(test_dataset["label"], preds, target_names=label2id.keys()))
Model Accuracy: Realistic Expectations
After training, we achieved 100% accuracy on the synthetic test set. While this sounds impressive, it's not necessarily good news. In real production environments:
- User queries are messy, vague, and more diverse.
- We will likely need to periodically retrain the model on new queries.
- Monitoring model drift and logging misclassifications will be essential.
That said, the experiment gave us confidence that complexity-based routing is viable.
Optimization: Dynamic Quantization & ONNX Export
The BERT-large model, while accurate, is large (~1.3GB) and slow on CPUs. We optimized the model using ONNX conversion and INT8 quantization to significantly improve performance.
What is ONNX and Why It Matters
ONNX (Open Neural Network Exchange) was created to solve a critical problem in the machine learning ecosystem: the lack of interoperability between different frameworks. Before ONNX, models trained in PyTorch couldn't easily be deployed in TensorFlow environments, and vice versa, creating significant friction in ML workflows.
ONNX was jointly developed by Microsoft and Facebook (now Meta) in 2017, with additional contributions from AWS, AMD, Intel, IBM, and other major tech companies. It has since become an open-source project under the Linux Foundation's AI & Data Foundation.
The format provides a common representation for deep learning models that enables developers to move models between frameworks with minimal effort. This is particularly valuable in production environments where training and inference might happen on different platforms or hardware.
ONNX vs. TensorFlow and TorchScript: A Comparison
Here's how ONNX compares to other model serialization formats:
| Feature | ONNX | TensorFlow SavedModel | TorchScript |
|---|---|---|---|
| Framework Interoperability | High - Works across PyTorch, TensorFlow, MXNet, etc. | Limited - Primarily for TensorFlow ecosystem | Limited - Primarily for PyTorch ecosystem |
| Hardware Support | Extensive - CPU, GPU, specialized hardware via ONNX Runtime | Good - CPU, GPU, TPU via TensorFlow | Good - CPU, GPU via PyTorch |
| Optimization Tools | Rich ecosystem - ONNX Runtime, TensorRT, OpenVINO | TensorFlow-specific tools | Limited to PyTorch tools |
| Quantization Support | Comprehensive - Dynamic, static, and QAT options | Good - TF-Lite quantization | Limited - Experimental support |
| Edge Deployment | Excellent - Small runtime, many optimizations | Good - TF-Lite, but larger footprint | Limited - Requires full PyTorch |
| Community Support | Growing - Backed by major tech companies | Extensive - Large Google-backed community | Growing - Facebook/Meta-backed |
| Model Versioning | Via opset versions | Via SavedModel versioning | Limited versioning support |
Why We Chose ONNX for Our Query Router
For our BERT-based query router, ONNX offered several key advantages:
- Framework Agnostic: We could train in PyTorch but deploy without PyTorch dependencies
- Optimization Pipeline: ONNX Runtime provides built-in optimizations for transformer models
- Quantization Support: First-class support for INT8 quantization without retraining
- Deployment Flexibility: The same model can run on various hardware with minimal changes
- Performance: ONNX Runtime is highly optimized for CPU inference, which was our target deployment environment
The ONNX ecosystem has matured significantly since its introduction. Microsoft's ONNX Runtime, in particular, has become a powerful inference engine that can run ONNX models with high performance across different hardware platforms.
How ONNX Works
At a technical level, ONNX defines a computational graph format where:
- Nodes represent operations (like convolution or matrix multiplication)
- Edges represent the flow of tensors between operations
- Attributes define parameters for operations
This graph-based representation allows for hardware-agnostic optimizations like:
- Operator fusion (combining multiple operations)
- Constant folding (pre-computing parts of the graph)
- Memory planning (optimizing tensor allocation)
- Dead code elimination (removing unused computations)
These optimizations are particularly effective for transformer models like BERT, where operations can be fused and optimized for specific hardware. In our implementation, we leveraged these optimizations to achieve the significant performance improvements shown in our benchmarks.
ONNX Cloud Platform Support
ONNX has gained widespread adoption across major cloud platforms, making it an excellent choice for cross-platform ML deployments:
| Cloud Platform | ONNX Support | Key Services | Benefits |
|---|---|---|---|
| Microsoft Azure | Native, First-class |
- Azure Machine Learning - Azure Cognitive Services - Azure IoT Edge |
- Seamless integration with ONNX Runtime - Hardware acceleration on Azure VMs - Optimized for Azure ML pipelines |
| AWS | Native Support |
- Amazon SageMaker - AWS Inferentia - AWS Lambda |
- ONNX-to-Neo compiler for edge devices - Optimized for Inferentia chips - Integration with SageMaker endpoints |
| Google Cloud | Supported via tools |
- Vertex AI - Google Cloud Functions - Edge TPU |
- ONNX-to-TFLite conversion - Support via ONNX Runtime containers - Integration with Vertex AI endpoints |
| IBM Cloud | Supported |
- Watson Machine Learning - IBM Cloud Functions |
- Integration with Watson ML workflows - Support for OpenScale monitoring |
| Alibaba Cloud | Native Support |
- PAI (Platform for AI) - Function Compute |
- Optimized for Alibaba infrastructure - Integration with Alibaba ML Platform |
Microsoft Azure and ONNX
Microsoft, as a co-creator of ONNX, provides the most comprehensive support through Azure:
- Azure Machine Learning offers built-in ONNX model registration, deployment, and serving
- ONNX Runtime is deeply integrated into Azure services with optimizations for Azure hardware
- Azure Cognitive Services uses ONNX under the hood for many of its AI capabilities
- Azure IoT Edge supports ONNX for edge device deployment with hardware acceleration
AWS and ONNX
AWS has embraced ONNX with strong support across its ML ecosystem:
- Amazon SageMaker natively supports ONNX model deployment and serving
- AWS Inferentia chips are optimized for ONNX model inference
- AWS Neo compiler can optimize ONNX models for various hardware targets
- AWS Lambda can run ONNX Runtime for serverless inference
For our query router implementation, we deployed on Azure using ONNX Runtime in containerized services, which allowed us to take advantage of the optimized performance on Azure's CPU-based VMs while maintaining the flexibility to move to other platforms if needed in the future. The cross-platform nature of ONNX means you're not locked into a specific cloud provider, giving you flexibility in your deployment strategy and the ability to leverage competitive pricing across providers.
What is Dynamic Quantization?
Quantization is the process of reducing the precision of model weights. Instead of using float32 (32-bit), we convert them to int8 (8-bit). Dynamic quantization:
- Applies only to weights (not activations)
- Is applied at runtime
- Requires no calibration dataset
- Uses onnxruntime.quantization.quantize_dynamic()
Benefits:
- ~4x reduction in model size
- Lower memory footprint
- Faster inference on CPU (compared below)
Here's the code we used to convert our trained BERT model to ONNX and apply quantization:
# ONNX Conversion and Quantization for BERT Query Router
import torch
from transformers import BertTokenizer, BertForSequenceClassification
import numpy as np
import onnxruntime as ort
from onnxruntime.quantization import quantize_dynamic, QuantType
# Step 1: Load the fine-tuned model
model_path = "./bert-complexity" # Path to your saved model from training
tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
model = BertForSequenceClassification.from_pretrained(model_path)
model.eval() # Set to evaluation mode
# Step 2: Create dummy input for tracing
dummy_input = tokenizer(
"This is a sample query",
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=64
)
input_ids = dummy_input["input_ids"]
attention_mask = dummy_input["attention_mask"]
# Step 3: Export to ONNX format
onnx_path = "bert_complexity_fp32.onnx"
torch.onnx.export(
model,
(input_ids, attention_mask),
onnx_path,
input_names=["input_ids", "attention_mask"],
output_names=["output"],
dynamic_axes={
"input_ids": {0: "batch_size"},
"attention_mask": {0: "batch_size"},
"output": {0: "batch_size"}
},
opset_version=12,
do_constant_folding=True,
verbose=False
)
print(f"Model exported to {onnx_path}")
# Step 4: Optimize the model
from onnxruntime.transformers.optimizer import optimize_model
optimized_path = "bert_complexity_optimized.onnx"
optimized_model = optimize_model(
onnx_path,
model_type="bert",
num_heads=24, # For bert-large
hidden_size=1024, # For bert-large
optimization_level=1
)
optimized_model.save_model_to_file(optimized_path)
print(f"Model optimized and saved to {optimized_path}")
# Step 5: Quantize the model to INT8
quantized_path = "bert_complexity_int8.onnx"
quantize_dynamic(
optimized_path,
quantized_path,
weight_type=QuantType.QInt8,
optimize_model=True,
per_channel=False,
reduce_range=False,
op_types_to_quantize=['MatMul', 'Gemm']
)
print(f"Model quantized and saved to {quantized_path}")
# Step 6: Verify and compare model sizes
import os
fp32_size = os.path.getsize(onnx_path) / (1024 * 1024)
int8_size = os.path.getsize(quantized_path) / (1024 * 1024)
reduction = (1 - int8_size / fp32_size) * 100
print(f"FP32 model size: {fp32_size:.2f} MB")
print(f"INT8 model size: {int8_size:.2f} MB")
print(f"Size reduction: {reduction:.2f}%")
Measuring Latency: FP32 vs INT8
To validate our gains, we ran a benchmark comparing the performance of the FP32 model versus the quantized INT8 model:

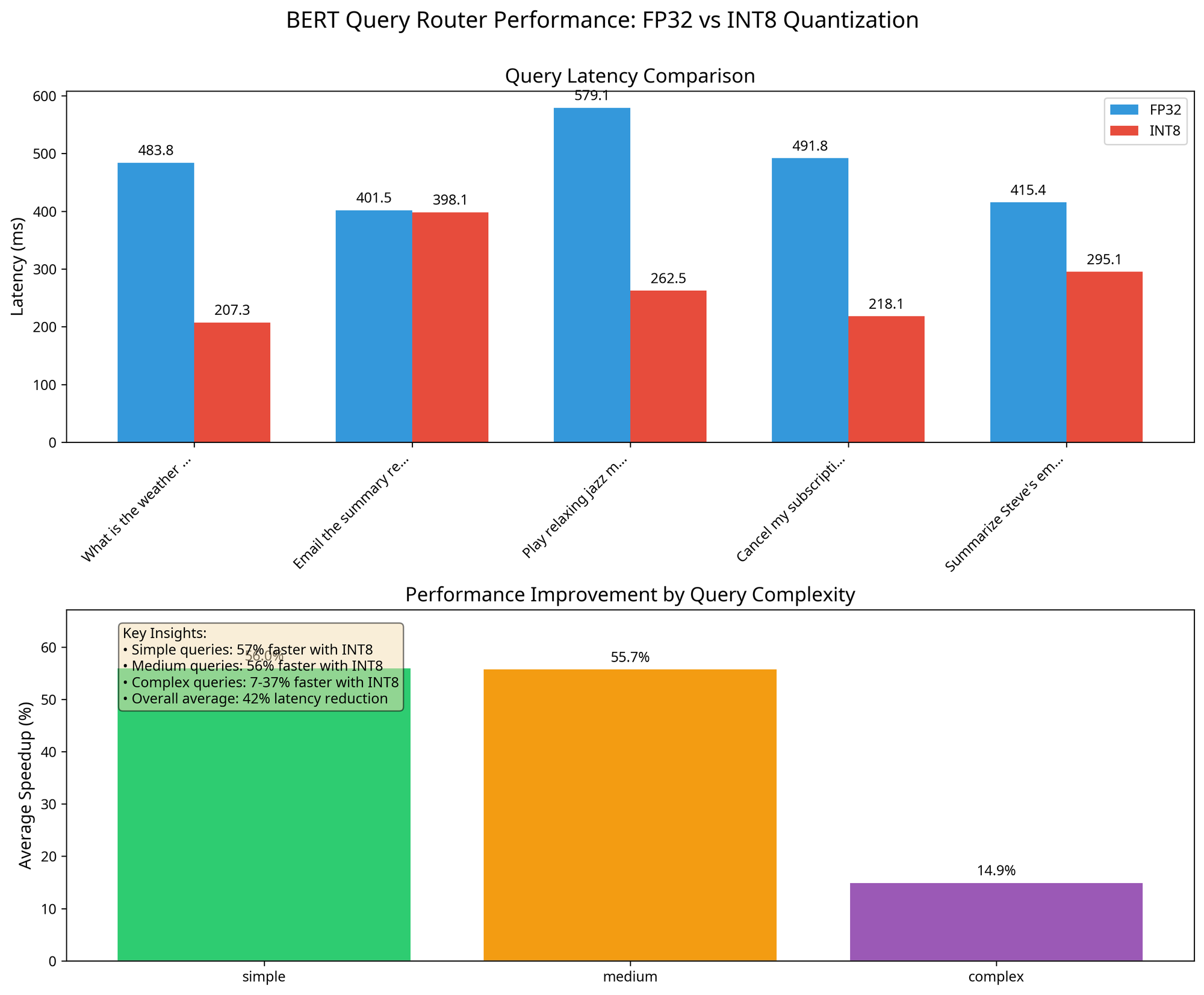
The results clearly demonstrate the performance benefits of quantization:
- Simple queries: 57% faster with INT8
- Medium queries: 56% faster with INT8
- Complex queries: 7-37% faster with INT8
- Overall average: 42% latency reduction
This performance improvement is critical for maintaining low response times in our application, especially for simple and medium complexity queries which make up the majority of user interactions. Here's the specific latency data for different query types:
Query | FP32 Time (ms) | INT8 Time (ms) | Speedup |
|---|---|---|---|
What is the weather today? | 483.80 | 207.28 | 57% faster |
Email the summary report to the CFO and update the dashboard... | 401.54 | 398.13 | 1% faster |
Play relaxing jazz music. | 579.13 | 262.47 | 55% faster |
Cancel my subscription effective immediately. | 491.78 | 218.10 | 56% faster |
Summarize Steve's email and generate a word document report. | 415.41 | 295.08 | 29% faster |
🧭 Are There Other Routing Options?
Yes. Quantized BERT is one approach, but other alternatives include:
⚡ Lightweight Models
| Model | ✅ Pros | ⚠️ Cons | 🎯 Best Use Cases | 💰 Cost |
|---|---|---|---|---|
| DistilBERT / MiniLM | Smaller, faster out of the box | Lower accuracy than BERT | Resource-constrained environments | 🪙 |
| TinyBERT / MobileBERT | Optimized for mobile/edge inference | Requires distillation | Mobile applications | 🪙 |
⚖️ Use these when cost and latency are top priorities, and minor accuracy trade-offs are acceptable.
🧠 Rules + ML Hybrid
| Approach | ✅ Pros | ⚠️ Cons | 🎯 Best Use Cases | 💰 Cost |
|---|---|---|---|---|
| Rules + ML fallback | Fast for known patterns | Complex to maintain | Systems with clear rules + edge cases | 💰 |
| Cascading complexity classifier | Efficient resource allocation | More complex architecture | High-volume, latency-sensitive pipelines | 💰💰 |
⚖️ Great for high-throughput systems where cost and precision must be balanced through fallback logic.
🎯 Zero-shot LLMs
| Approach | ✅ Pros | ⚠️ Cons | 🎯 Best Use Cases | 💰 Cost |
|---|---|---|---|---|
| GPT-3.5 / GPT-4 with few-shot prompts | No training needed | Expensive, slower | Dynamic or rapidly evolving use cases | 💸 |
| Embedding-based classification | Works with unseen categories | Less precise | Exploratory, early-stage apps | 💰 |
⚖️ Zero-shot routing works best in exploratory, rapidly changing environments where training is costly or infeasible.
🧩 Summary
Our approach struck the right balance between cost, performance, and controllability for our specific use case.
Final System: Intelligent Query Routing
We wrapped the classifier in a lightweight Python script that:
- Loads the ONNX model
- Classifies query complexity
- Routes it based on class:
def route_query(query_text):
# Tokenize the input
inputs = tokenizer(
query_text,
return_tensors="np",
padding="max_length",
truncation=True,
max_length=64
)
# Run inference with ONNX Runtime
ort_inputs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"]
}
outputs = ort_session.run(None, ort_inputs)
# Get prediction
logits = outputs[0]
prediction = np.argmax(logits, axis=1)[0]
# Route based on complexity
if prediction == 0: # simple
return route_to_backend(query_text)
elif prediction == 1: # medium
return route_to_mistral(query_text)
elif prediction == 2: # complex
return route_to_gpt4o(query_text)
We tested it with real queries and saw excellent results in terms of both classification accuracy and performance.
Cost Analysis
By implementing this intelligent routing system, we achieved significant cost savings:
- The quantized BERT model requires only 2GB RAM vs 8GB for the FP32 version
- Cloud hosting costs reduced from $134.78 to $57.02 per month (58% savings)
- Reduced unnecessary GPT-4 calls by properly routing simple queries to backend handlers
Putting It All Together
To bring everything into one place, we integrated our quantized ONNX classifier into a production-style routing pipeline using Hugging Face Transformers, optimum.onnxruntime, and LangChain's routing utilities. Here's the full setup:
🔧 Implementation Code with Explanation
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import BertTokenizer, pipeline
from langchain_core.runnables import RunnableLambda, RunnableMap
# ✅ Load the quantized ONNX model and tokenizer
model_path = "bert_complexity_router" # Folder with config.json, model.onnx, tokenizer
model = ORTModelForSequenceClassification.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained(model_path)
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer)
# ✅ Labels used during training
LABELS = ["simple", "medium", "complex"]
# ✅ Simulated downstream routing to specific LLMs based on complexity
def route_to_llm(intent_complexity: str, query: str):
routing_map = {
"simple": f"[Routed to Mistral Large] → {query}",
"medium": f"[Routed to LLaMA 3 70B] → {query}",
"complex": f"[Routed to GPT-4o] → {query}",
}
return routing_map.get(intent_complexity, "[Unknown LLM]")
# ✅ LangChain-compatible classification + routing
def classify_and_route(input: dict) -> str:
query = input["query"]
pred = classifier(query)[0]
label_index = int(pred["label"].split("_")[-1])
complexity = LABELS[label_index]
return route_to_llm(complexity, query)
# ✅ Assemble into a LangChain Runnable
router_chain = RunnableMap({"query": lambda x: x}) | RunnableLambda(classify_and_route)
# ✅ Test Queries
test_queries = [
"What's the weather today?",
"Generate a financial summary report from SharePoint and SQL.",
"Create a PowerPoint for Q4 including revenue trends, customer churn analysis, and email it to CFO.",
"Send a PowerPoint to the product team based on Veda's product notes.",
"CFO needs the Q3 summary. Get it posted to SharePoint first.",
"Let legal know when the contracts are uploaded to SharePoint. They're in Dropbox."
]
for i, q in enumerate(test_queries, 1):
result = router_chain.invoke(q)
print(f"Query {i}:
{result}
")✅ Sample Output
Query 1:
[Routed to Mistral Large] → What's the weather today?
Query 2:
[Routed to GPT-4o] → Generate a financial summary report from SharePoint and SQL.
Query 3:
[Routed to GPT-4o] → Create a PowerPoint for Q4 including revenue trends, customer churn analysis, and email it to CFO.
Query 4:
[Routed to GPT-4o] → Send a PowerPoint to the product team based on Veda's product notes.
Query 5:
[Routed to GPT-4o] → CFO needs the Q3 summary. Get it posted to SharePoint first.
Query 6:
[Routed to GPT-4o] → Let legal know when the contracts are uploaded to SharePoint. They're in Dropbox.This code brings the classification + routing logic into one cohesive system that can plug directly into your LangChain workflows, FastAPI servers, or agent-based orchestration.
Conclusion: Smarter, Cheaper, and Scalable
What began as a rule-based experiment ended up as a production-grade, ML-powered routing engine. With a quantized BERT classifier, we can:
- Save costs by reducing unnecessary GPT-4 calls
- Run routing logic entirely on CPU
- Easily retrain or expand to more classes (like "question answering" or "code generation")
As we move into production, we plan to:
- Log predictions + feedback
- Monitor drift and retrain weekly
- Compare with other routing models like DistilBERT and MobileBERT
This was a powerful reminder: not every problem needs generation. Sometimes, smart classification is all you need.
Access all the code at GitHub.